
在Linux中经常发现空闲内存很少,似乎所有的内存都被系统占用了,感觉是内存不够用了。其实不然,这是Linux内存管理的一个优秀的特征,主要特点是,物理物理内存有多大,Linux都将其充分利用,将一些程序调用过的硬盘数据读入内存(buffer/Cache),利用内存读写的高速特性来提供Linux系统的数据访问性能高。
1. 什么是Page Cache
当程序去读文件,可以通过read也可以通过mmap去读,当你通过任何一种方式从磁盘读取文件时,内核都会给你申请一个Page cache,用来缓存磁盘上的内容。这样读过一次的数据,下次读取的时候就直接从Page cache里去读,提升了系统的整体性能。
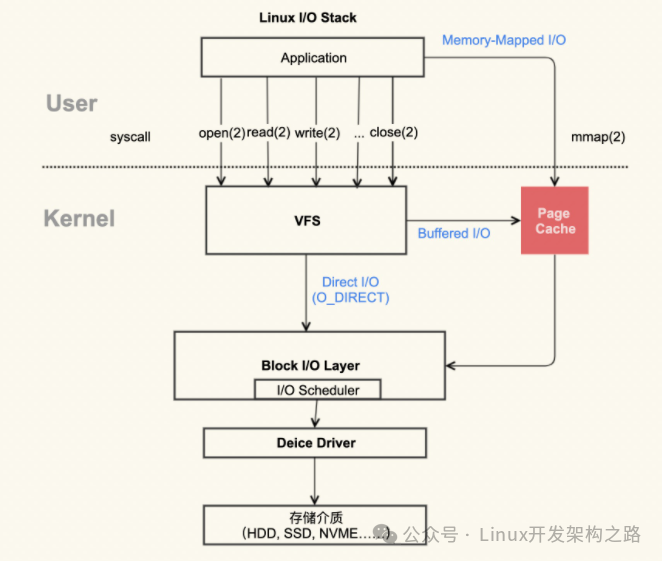
对于Linux可以怎么来观察Page Cache呢?其实,在Linux上直接可以通过命令来看,他们的内容是一致的。
首先最简单的是free命令来看一下

首先我们来看看buffers和cached的定义
-
Buffers 是对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,通常不会特别大(20MB 左右)。这样,内核就可以把分散的写集中起来,统一优化磁盘的写入,比如可以把多次小的写合并成单次大的写等等。
-
Cached 是从磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据。这样,下次访问这些文件数据时,就可以直接从内存中快速获取,而不需要再次访问缓慢的磁盘
buffer cache和page cache在处理上是保持一致的,但是存在概念上的差别,page cache是针对文件的cache,buffer是针对磁盘块数据的cache,仅此而已。
2. 为什么需要page cache
通过上图,我们可以直观的看到,标准的I/O和内存映射会先将数据写到Page Cache,这样做是通过减小I/O次数来提升读写效率。我们来实际的例子,我们先来生成一个1G的文件,然后通过把Page cache清空,确保文件内容不在内存中,一次来比较第一次和第二次读文件的差异。
通过这两次详细的过程,可以看出第一次读取文件的耗时远小于第二次耗时
-
因为第一次读取的时候,由于文件内容已经在生成文件的时候已经存在,所以直接从内存读取的数据
-
第二次会将缓存数据清掉,会从磁盘上读取内容,磁盘I/O比较耗时,内存相比磁盘会快很多
所以Page Cache存在的意义,减小I/O,提升应用的I/O速度。对于Page Cache方案,我们采用原则如下
-
如果不想增加应用的复杂度,我们优先使用内核管理的Page Cache
-
如果应用程序需要做精确控制,就需要不走Cache,因为Page Cache有它自身的局限性,就是对于应用程序太过于透明了,以至于很难有好的控制方法。
3. Page Cache是如何“诞生的”
Page Cache的产生有两种不同的方式
-
Buffered I/O(标准I/O)
-
Memory-Mapped I/O(储存映射IO)
这两种方式分别都是如何产生Page Cache的呢?
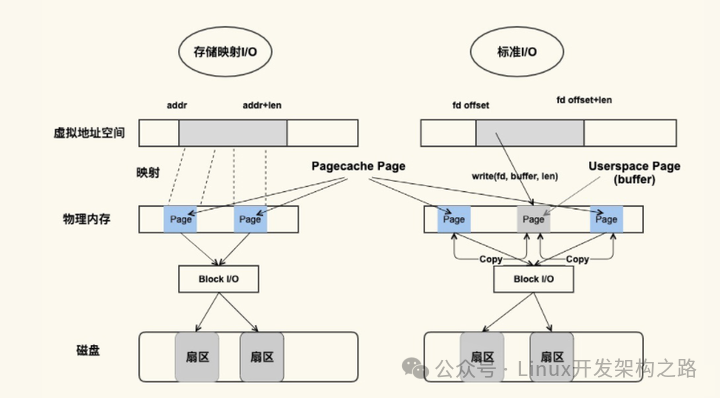
从图中可以看到,二者是都能产生Page Cache,但是二者还是有差异的
-
标准I/O是写的话用户缓存区(User page对应的内存),然后再将用户缓存区里的数据拷贝到内核缓存区(Pagecahe Page对应的内存);如果是读的话则是内核缓存区拷贝到用户缓存区,再从用户缓存区去读数据,也就是Buffer和文件内容不存在映射关系
-
储存映射IO,则是直接将Page Cache的Page给映射到用户空间,用户直接读写PageCache Page里的数据
从原理来说储存映射I/O要比标准的I/O效率高一些,少了“用户空间到内核空间互相拷贝”的过程。下图是一张简图描述这个过程:
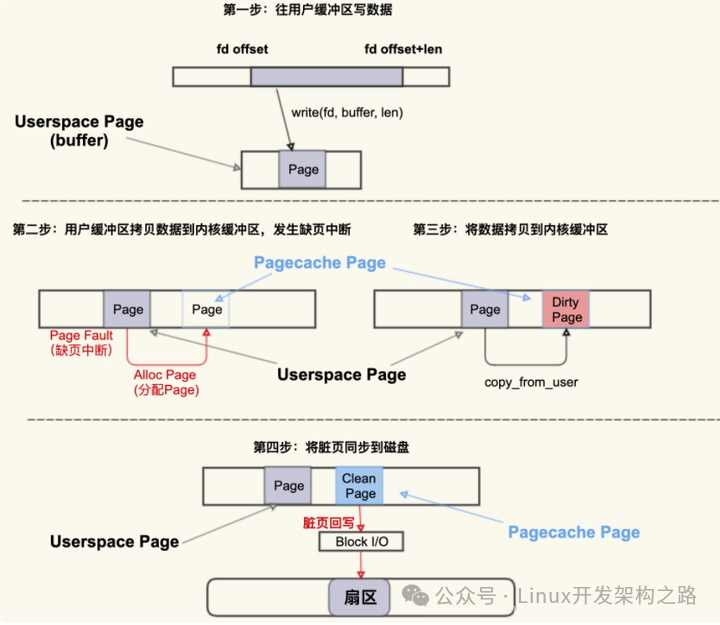
-
首先,往用户缓冲区Buffer(用户空间)写入数据,然后,Buffer中的数据拷贝到内核的缓冲区(这个是PageCache Page)
-
如果内核缓冲区还没有这个page,就会发生Page Fault会去分配一个Page;如果有,就直接用这个PageCache的Page
-
拷贝结束后,该PageCache的Page是一个Dirty Page脏页,然后该Dirty Page中的内容会同步到磁盘,同步到磁盘后,该PageCache Page变味Clean Page并且继续存在系统中
我们可以通过手段来测试脏页,如下图所示
-
nr_dirty:表示系统中积压了多少脏页(单位为Page 4KB)
-
nr_writeback则表示有多少脏页正在回写到磁盘中(单位为Page 4KB)
总结
读过程,当内核发起一个读请求时候
-
先检查请求的数据是否缓存到page Cache中,如果有则直接从内存中读取,不访问磁盘
-
如果Cache中没有请求数据,就必须从磁盘中读取数据,然后内核将数据缓存到Cache中
-
这样后续请求就可以命中cache,page可以只缓存一个文件的部分内容,不需要把整个文件都缓存
写过程,当内核发起一个写请求时候
-
直接写到Cache中,内核会将被写入的Page标记为dirty,并将其加入到dirty list中
-
内核会周期性的将dirty list中的page回写到磁盘上,从而使磁盘上的数据和内存中缓存的数据一致
4. page cache是如何“死亡”
free命令中的buffer/cache中的是“活着”的Page Cache,那他们是什么时候被回收的呢?
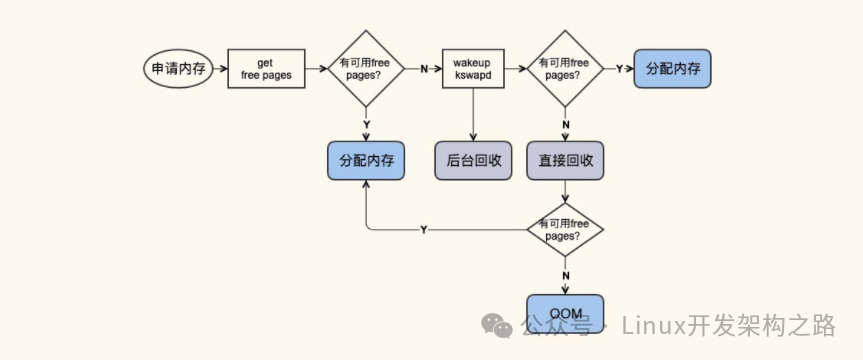
回收的主要方式有两种
-
直接回收:
-
后台回收:
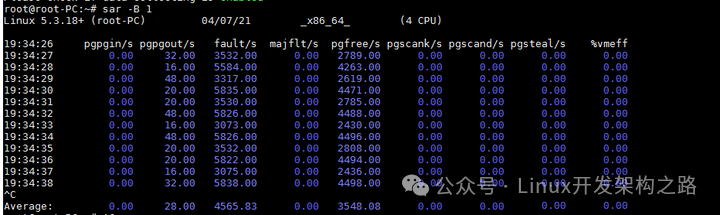
观察Page cache直接回收和后台回收最简单方便的方式,借助这个工具,可以明确观察内存回收行为
-
pgscank/s: kswapd(后台回收线程)每秒扫面的Page个数
-
pgscand/s: Application在内存申请过程中每秒直接扫描的Page个数
-
pgsteal/s: 扫面的page中每秒被回收的个数
-
%vmeff: pgsteal/(pgscank+pgscand),回收效率,越接近100说明系统越安全,越接近0,说明系统内存压力越大
-
pgpgin/s 表示每秒从磁盘或SWAP置换到内存的字节数(KB)
-
pgpgout/s: 表示每秒从内存置换到磁盘或SWAP的字节数(KB)
-
fault/s: 每秒钟系统产生的缺页数,即主缺页与次缺页之和(major + minor)
-
majflt/s: 每秒钟产生的主缺页数.
-
pgfree/s: 每秒被放入空闲队列中的页个数
需要C/C++ Linux服务器架构师学习资料加qun579733396获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享

5.Page Cache性能优化
通过前文我们知道了Linux是用Cache/Buffer缓存数据,提高系统的I/O性能,且有一个回刷任务在适当时候把脏数据回刷到储存介质中。那么接下来我们重点学习优化机制。
包括以下内容
-
什么时候触发回刷?
-
脏数据达到多少阈值还是定时触发呢?
-
内核是如何做到回写机制的
(1) 配置概述
Linux内核在/proc/sys/vm中有透出数个配置文件,可以对触发回刷的时机进行调整。内核的回刷进程是怎么运作的呢?这数个配置文件有什么作用呢?
在/proc/sys/vm中有以下文件与回刷脏数据密切相关:
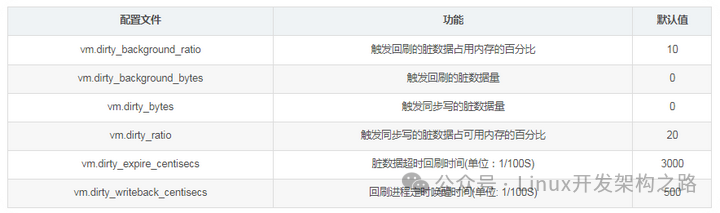
vm.dirty_background_ratio:
内存可以填充脏数据的百分比,这些脏数据稍后会写入磁盘。pdflush/flush/kdmflush这些后台进程会稍后清理脏数据。比如,我有32G内存,那么有3.2G(10%的比例)的脏数据可以待着内存里,超过3.2G的话就会有后台进程来清理。
vm.dirty_ratio
可以用脏数据填充的绝对最大系统内存量,当系统到达此点时,必须将所有脏数据提交到磁盘,同时所有新的I/O块都会被阻塞,直到脏数据被写入磁盘。这通常是长I/O卡顿的原因,但这也是保证内存中不会存在过量脏数据的保护机制。
vm.dirty_background_bytes 和 vm.dirty_bytes
另一种指定这些参数的方法。如果设置 xxx_bytes版本,则 xxx_ratio版本将变为0,反之亦然。
vm.dirty_expire_centisecs
指定脏数据能存活的时间。在这里它的值是30秒。当 pdflush/flush/kdmflush 在运行的时候,他们会检查是否有数据超过这个时限,如果有则会把它异步地写到磁盘中。毕竟数据在内存里待太久也会有丢失风险。
vm.dirty_writeback_centisecs
指定多长时间 pdflush/flush/kdmflush 这些进程会唤醒一次,然后检查是否有缓存需要清理。
实际上dirty_ratio的数字大于dirty_background_ratio,是不是就不会达到dirty_ratio呢?
首先达到dirty_background_ratio的条件后触发flush进程进行异步的回写操作,但是这一过程中应用进程仍然可以进行写操作,如果多个应用写入的量大于flush进程刷出的量,那自然就会达到vm.dirty_ratio这个参数所设定的阙值,此时操作系统会转入同步地进行脏页的过程,阻塞应用进程。
(2)配置实例
单纯的配置说明毕竟太抽象。结合网上的分享,我们看看在不同场景下,该如何配置?
场景1:尽可能不丢数据
有些产品形态的数据非常重要,例如行车记录仪。在满足性能要求的情况下,要做到尽可能不丢失数据。
/* 此配置不一定适合您的产品,请根据您的实际情况配置 */dirty_background_ratio = 5dirty_ratio = 10dirty_writeback_centisecs = 50dirty_expire_centisecs = 100
这样的配置有以下特点:
-
当脏数据达到可用内存的5%时唤醒回刷进程
-
脏数据达到可用内存的10%时,应用每一笔数据都必须同步等待
-
每隔500ms唤醒一次回刷进程
-
当脏数据达到可用内存的5%时唤醒回刷进程
由于发生交通事故时,行车记录仪随时可能断电,事故前1~2s的数据尤为关键。因此在保证性能满足不丢帧的情况下,尽可能回刷数据。
此配置通过减少Cache,更加频繁唤醒回刷进程的方式,尽可能让数据回刷。
此时的性能理论上会比每笔数据都O_SYNC略高,比默认配置性能低,相当于用性能换数据安全。
场景2:追求更高性能
有些产品形态不太可能会掉电,例如服务器。此时不需要考虑数据安全问题,要做到尽可能高的IO性能。
/* 此配置不一定适合您的产品,请根据您的实际情况配置 */dirty_background_ratio = 50dirty_ratio = 80dirty_writeback_centisecs = 2000dirty_expire_centisecs = 12000
这样的配置有以下特点:
-
当脏数据达到可用内存的50%时唤醒回刷进程
-
当脏数据达到可用内存的80%时,应用每一笔数据都必须同步等待
-
每隔20s唤醒一次回刷进程
-
内存中脏数据存在时间超过120s则在下一次唤醒时回刷
与场景1相比,场景2的配置通过 增大Cache,延迟回刷唤醒时间来尽可能缓存更多数据,进而实现提高性能
场景3:突然的IO峰值拖慢整体性能
什么是IO峰值?突然间大量的数据写入,导致瞬间IO压力飙升,导致瞬间IO性能狂跌,对行车记录仪而言,有可能触发视频丢帧。
这样的配置有以下特点:
-
当脏数据达到可用内存的5%时唤醒回刷进程
-
当脏数据达到可用内存的80%时,应用每一笔数据都必须同步等待
-
每隔5s唤醒一次回刷进程
-
内存中脏数据存在时间超过30s则在下一次唤醒时回刷
这样的配置,通过增大Cache总容量,更加频繁唤醒回刷的方式,解决IO峰值的问题,此时能保证脏数据比例保持在一个比较低的水平,当突然出现峰值,也有足够的Cache来缓存数据。
(3)内核演变
对于回写方式在之前的2.4内核中,使用 bdflush的线程专门负责writeback的操作,因为磁盘I/O操作很慢,而现代操作系统通常具有多个块设备,如果bdflush在其中一个块设备上等待I/O操作的完成,可能需要很长的时间,此时其他块设备还处于空闲状态,这时候,单线程模式的bdflush就称为了影响性能的瓶颈。而此时bdflush是没有周期扫描功能,因此需要配合kupdate线程一起使用。
bdflush 存在的问题:
整个系统仅仅只有一个 bdflush 线程,当系统回写任务较重时,bdflush 线程可能会阻塞在某个磁盘的I/O上,
导致其他磁盘的I/O回写操作不能及时执行
于是在2.6内核中,bdflush机制就被pdflush取代,pdflush是一组线程,根据块设备I/O负载情况,数量从最少的2个到最多的8个不等,如果1S内都没有空闲的pdflush线程可用,内核将创建一个新的pdflush线程,反之某个pdflush线程空闲超过1S,则该线程将会被销毁。pdflush 线程数目是动态的,取决于系统的I/O负载。它是面向系统中所有磁盘的全局任务的。
pdflush 存在的问题:
pdflush的数目是动态的,一定程度上缓解了 bdflush 的问题。但是由于 pdflush 是面向所有磁盘的,所以有可能出现多个 pdflush 线程全部阻塞在某个拥塞的磁盘上,同样导致其他磁盘的I/O回写不能及时执行。
于是在内最新的内核中,直接将一个块设备对应一个thread,这种内核线程被称为flusher threads,线程名为“Writeback",执行体为"wb_workfn",通过workqueue机制实现调度。
(4)内核实现
由于内核page cache的作用,写操作实际被延迟写入。当page cache里的数据被用户写入但是没有刷新到磁盘时,则该page为脏页(块设备page cache机制因为以前机械磁盘以扇区为单位读写,引入了buffer_head,每个4K的page进一步划分成8个buffer,通过buffer_head管理,因此可能只设置了部分buffer head为脏)。
脏页在以下情况下将被回写(write back)到磁盘上:
-
脏页在内存里的时间超过了阈值。
-
系统的内存紧张,低于某个阈值时,必须将所有脏页回写。
-
用户强制要求刷盘,如调用sync()、fsync()、close()等系统调用。
以前的Linux通过pbflush机制管理脏页的回写,但因为其管理了所有的磁盘的page/buffer_head,存在严重的性能瓶颈,因此从Linux 2.6.32开始,脏页回写的工作由bdi_writeback机制负责。bdi_writeback机制为每个磁盘都创建一个线程,专门负责这个磁盘的page cache或者buffer cache的数据刷新工作,以提高I/O性能。
在 kernel/sysctl.c中列出了所有的配置文件的信息
这些值在mm/page-writeback.c中有全局变量定义
通过ps -aux,我们可以看到writeback的内核进程

这实际上是一个工作队列对应的进程,在default_bdi_init()中创建(mm/backing-dev.c)
回刷进程的核心是函数wb_workfn(),通过函数wb_init()绑定。
唤醒回刷进程的操作是这样的
表示唤醒的回刷任务在工作队列writeback中执行,这样,就把工作队列和回刷工作绑定了,重点看看这个接口做了些什么工作
-
正常路径,rescue workerrescue内核线程,内存紧张时创建新的工作线程可能会失败,如果内核中有会需要回收的内存,就调用wb_do_writeback进行回收
-
如果当前workqueue不能获得足够的worker进行处理,只提交一个work并限制写入1024个pages
这也过程代码较多,暂不去深入分析,重点关注相关的配置是如何起作用的。
(5) 触发回写方式
触发writeback的地方主要有以下几处:
5.1 主动发起
-
手动执行sysn命令
-
syncfs系统调用
-
直接内存回收,内存不足时调用
-
分配内存空间不足,触发回写脏页腾出内存空间
-
remount/umount操作,需要先将脏页写回
5.2 空间层面
当系统的“dirty”的内存大于某个阈值,该阈值是在总共的“可用内存”(包括free pages 和reclaimable pages)中的占比。
参数“dirty_background_ratio”(默认值10%),或者是绝对字节数“dirty_background_bytes”(默认值为0,表示生效)。两个参数只要谁先达到即可执行,此时就会交给专门负责writeback的background线程去处理。
参数“dirty_ratio”(默认值30%)和“dirty_bates”(默认值为0,表示生效),当“dirty”的内存达到这个比例或数量,进程则会停下write操作(被阻塞),先把“dirty”进行writeback。
5.3 时间层面
周期性的扫描,扫描间隔用参数:dirty_writeback_interval表示,以毫秒为单位。发现存在最近一次更新时间超过某个阈值(参数:dirty_expire_interval,单位毫秒)的pages。如果每个page都维护最近更新时间,开销会很大且扫描会很耗时,因此具体实现不会以page为粒度,而是按inode中记录的dirtying-time来计算。
(6)总结
文件缓存是一项重要的性能改进,在大多数情况下,读缓存在绝大多数情况下是有益无害的(程序可以直接从RAM中读取数据)。写缓存比较复杂,Linux内核将磁盘写入缓存,过段时间再异步将它们刷新到磁盘。这对加速磁盘I/O有很好的效果,但是当数据未写入磁盘时,丢失数据的可能性会增加。
 0
0







