
1.内存原理
1.1.内存映射
虚拟地址空间
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样进程就可以很方便地访问内存,更确切地说是访问虚拟内存。
虚拟地址空间内部
-
虚拟地址空间的内部又被分为 内核空间 和 用户空间 两部分
-
不同字长(单个 CPU 指令可以处理数据的最大长度)的处理器,地址空间的范围也不同
比如最常见的 32 位和 64 位,如下所示:
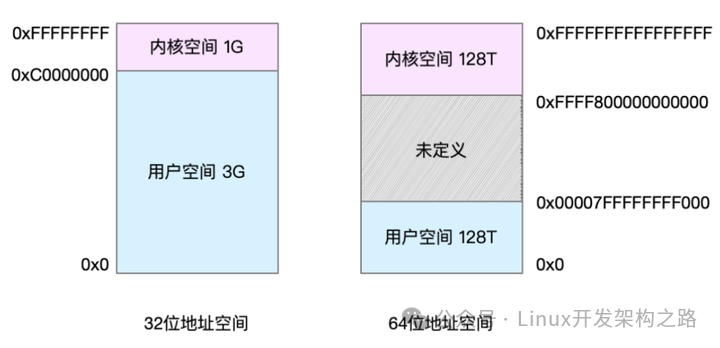
-
32 位系统的内核空间占用 1G,位于最高处,剩下的 3G 是用户空间
-
64 位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的
进程的用户态 和 内核态
进程在用户态时,只能访问用户空间内存;只有进入内核态后,才可以访问内核空间内存。虽然每个进程的地址空间都包含了内核空间,但这些内核空间,其实关联的都是相同的物理内存。这样,进程切换到内核态后,就可以很方便地访问内核空间内存。
为什么会有内存映射
既然每个进程都有一个这么大的地址空间,那么所有进程的虚拟内存加起来,自然要比实际的物理内存大得多。
所以,并不是所有的虚拟内存都会分配物理内存,只有那些实际使 用的虚拟内存才分配物理内存,并且分配后的物理内存,是通过内存映射来管理的。
什么是内存映射
内存映射,其实就是将虚拟内存地址映射到物理内存地址。为了完成内存映射,内核为每 个进程都维护了一张页表,记录虚拟地址与物理地址的映射关系,如下图所示:
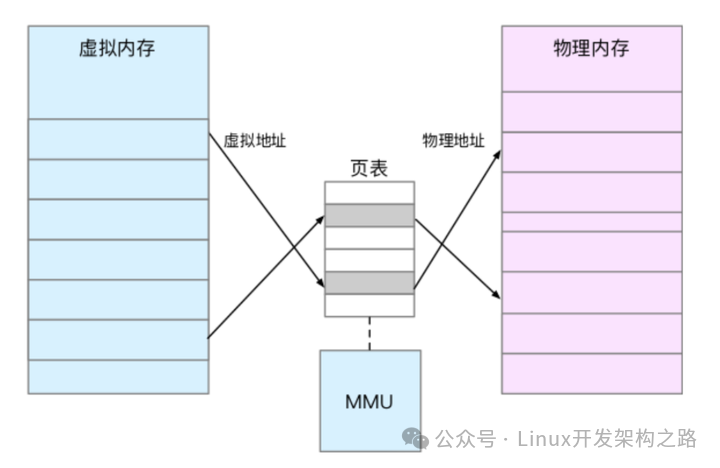
-
页表实际上存储在 CPU 的内存管理单元 MMU 中
-
正常情况下,处理器就可以直接通过硬件,找出要访问的内存
-
在页表的映射下,进程就可以通过虚拟地址来访问物理内存了
那么具体到一个 Linux 进程中,这些内存又是怎么使用的呢?
1.2.虚拟内存空间分布
首先,我们需要进一步了解虚拟内存空间的分布情况。用户空间内存,其实又被分成了多个不同的段。以 32 位系统为例:
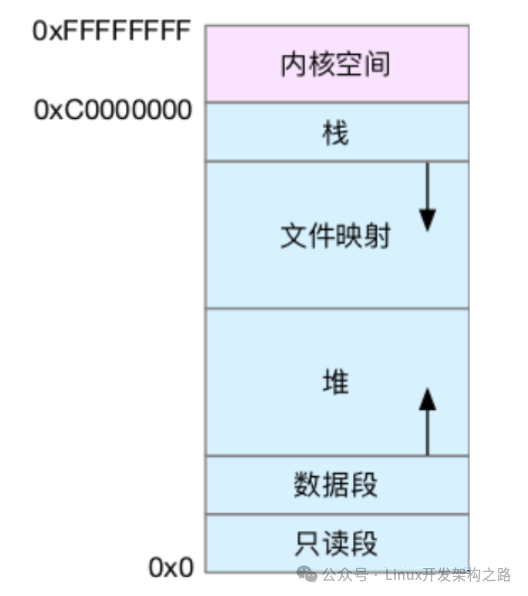
通过图可以看到,用户空间内存,从低到高分别是五种不同的内存段。
-
只读段,包括代码和常量等。
-
数据段,包括全局变量等。
-
堆,包括动态分配的内存,从低地址开始向上增长。
-
文件映射段,包括动态库、共享内存等,从高地址开始向下增长。
-
栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB。
在这五个内存段中,堆和文件映射段的内存是动态分配的。
1.3.SWAP运行原理
Swap 是把一块磁盘空间或者一个本地文件,当成内存来使用。它包括换出和换入两个过程。
-
所谓换出,就是把进程暂时不用的内存数据存储到磁盘中,并释放这些数据占用的内存。
-
而换入,则是在进程再次访问这些内存的时候,把它们从磁盘读到内存中来。
一个很典型的场景就是,即使内存不足时,有些应用程序也并不想被 OOM 杀死,而是希望能缓一段时间,等待人工介入,或者等系统自动释放其他进程的内存,再分配给它。
除此之外,我们常见的笔记本电脑的休眠和快速开机的功能,也基于 Swap 。休眠时,把系统的内存存入磁盘,这样等到再次开机时,只要从磁盘中加载内存就可以。这样就省去了很多应用程序的初始化过程,加快了开机速度。
既然 Swap 是为了回收内存,那么 Linux到底在什么时候需要回收内存呢?前面一直在说内存资源紧张,又该怎么来衡量内存是不是紧张呢?
一个最容易想到的场景就是,有新的大块内存分配请求,但是剩余内存不足。这个时候系统就需要回收一部分内存,进而尽可能地满足新内存请求。这个过程通常被称为 直接内存回收 。
除了直接内存回收,还有一个专门的内核线程用来 定期回收内存 ,也就是 kswapd0。为了衡量内存的使用情况,kswapd0 定义了三个内存阈值(watermark,也称为水位),分别是页最小阈值(pages_min)、页低阈值(pages_low)和页高阈值(pages_high)。剩余内存,则使用 pages_free 表示
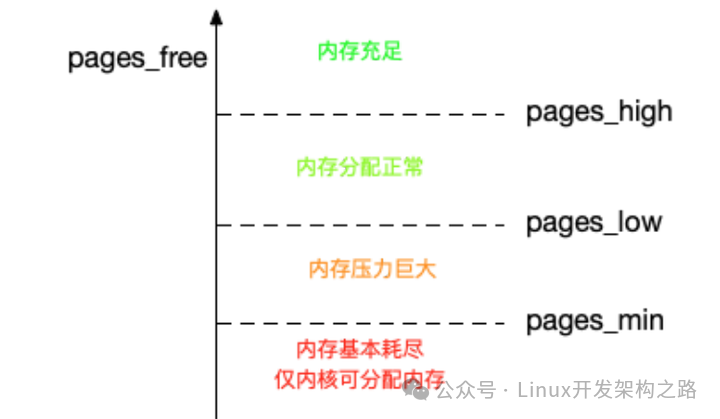
kswapd0 定期扫描内存的使用情况,并根据剩余内存落在这三个阈值的空间位置,进行内存的回收操作。
-
剩余内存小于页最小阈值,说明进程可用内存都耗尽了,只有内核才可以分配内存。
-
剩余内存落在页最小阈值和页低阈值中间,说明内存压力比较大,剩余内存不多了。这时 kswapd0 会执行内存回收,直到剩余内存大于高阈值为止。
-
剩余内存落在页低阈值和页高阈值中间,说明内存有一定压力,但还可以满足新内存请求。
-
剩余内存大于页高阈值,说明剩余内存比较多,没有内存压力。
可以看到,一旦剩余内存小于页低阈值,就会触发内存的回收。这个页低阈值,其实可以通过内核选项/proc/sys/vm/min_free_kbytes 来间接设置。min_free_kbytes 设置了页最小阈值,而其他两个阈值,都是根据页最小阈值计算生成的,计算方法如下 :
pages_low = pages_min*5/4 pages_high = pages_min*3/2
需要C/C++ Linux服务器架构师学习资料加qun579733396获取(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
2.内存性能统计信息
2.1.内存系统使用量
free工具显示系统内存情况
[root@centos7-2 ~]# free total used free shared buff/cache available Mem: 999720 550508 283544 6844 165668 279124 Swap: 2097148 0 097148
所有数值默认都是以字节(kb)为单位
-
第一行 Mem:物理内存
-
第二行 Swap:交换分区
可以看到,free 输出的是一个表格,其中的数值都默认以字节为单位。表格总共有两行六列,这两行分别是物理内存 Mem 和交换分区 Swap 的使用情况,而六列中,每列数据 的含义分别为:
-
第一列,total 是总内存大小;
-
第二列,used 是已使用内存的大小,包含了共享内存;
-
第三列,free 是未使用内存的大小;
-
第四列,shared 是共享内存的大小;
-
第五列,buw/cache 是缓存和缓冲区的大小;
-
最后一列,available 是新进程可用内存的大小。
这里尤其注意,最后一列的可用内存 available 。available 不仅包含未使用内存,还包括了可回收的缓存,所以一般会比未使用内存更大。不过,并不是所有缓存都可以回收,因为有些缓存可能正在使用中。不过,我们知道,free 显示的是整个系统的内存使用情况。
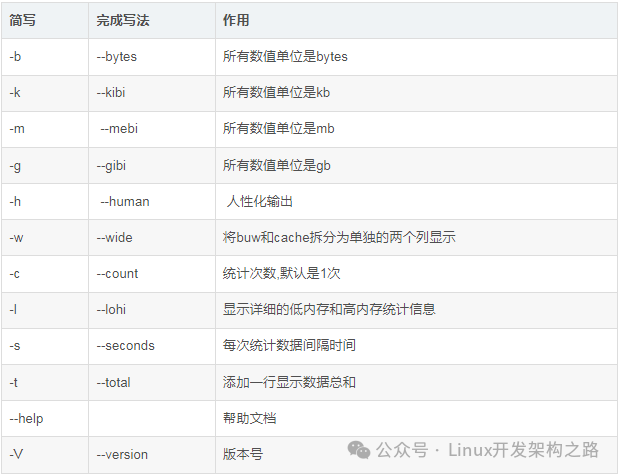
free命令参数
top指令
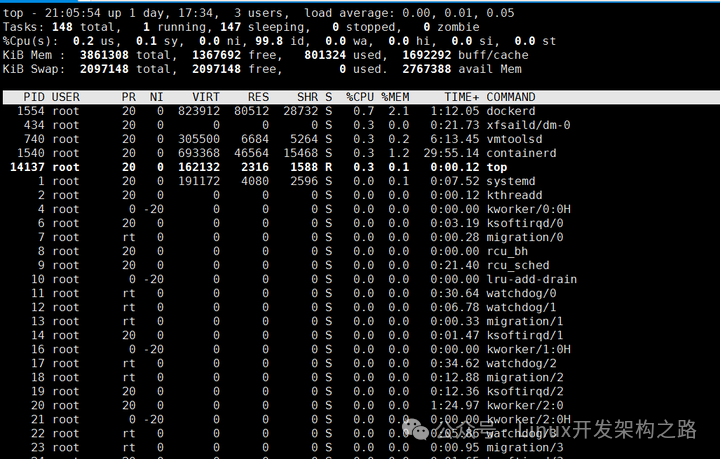
第一行:输出系统任务队列信息

-
21:08:13:系统当前时间
-
up 1 day:系统开机后到现在的总运行时间
-
3 user:当前登录用户数
-
load average: 0.12, 0.08, 0.06:系统负载,系统运行队列的平均利用率,可认为是可运行进程平均数;三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值
第二行:任务进程信息

-
total:系统全部进程的数量
-
running:运行状态的进程数量
-
sleeping:睡眠状态的进程数量
-
stoped:停止状态的进程数量
-
zombie:僵尸进程数量
第三行:CPU信息

-
us:用户空间占用CPU百分比
-
sy:内核空间占用CPU百分比
-
ni:已调整优先级的用户进程的CPU百分比
-
id:空闲CPU百分比,越低说明CPU使用率越高
-
wa:等待IO完成的CPU百分比
-
hi:处理硬件中断的占用CPU百分比
-
si:处理软中断占用CPU百分比
-
st:虚拟机占用CPU百分比
第四行:物理内存信息

以下内存单位均为MB
-
total:物理内存总量
-
free:空闲内存总量
-
used:使用中内存总量
-
buw/cache:用于内核缓存的内存量
第五行:交换区内存信息

-
total:交换区总量
-
free:空闲交换区总量
-
used:使用的交换区总量
-
avail Mem:可用交换区总量
注:如果used不断在变化, 说明内核在不断进行内存和swap的数据交换,说明内存真的不够用了
进行信息区
-
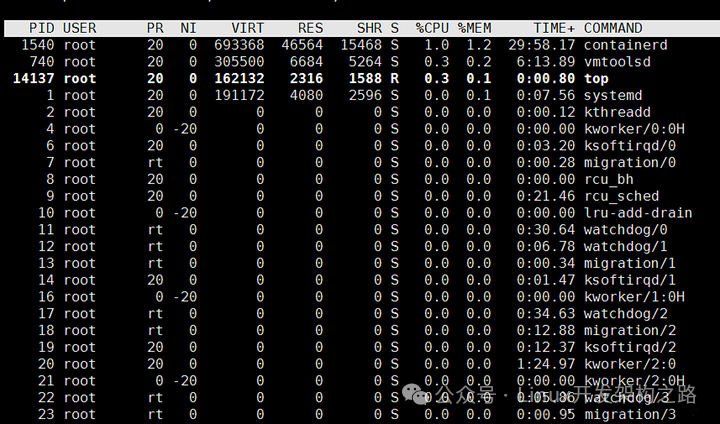
top 输出界面的顶端,也显示了系统整体的内存使用情况,这些数据跟 free 类似。
-
PID:进程号
-
USER:运行进程的用户
-
PR:优先级
-
NI:nice值。负值表示高优先级,正值表示低优先级
-
VIRT 是进程虚拟内存的大小,只要是进程申请过的内存,即便还没有真正分配物理内存,也会计算在内。
-
RES 是常驻内存的大小,也就是进程实际使用的物理内存大小,但不包括 Swap 和共享 内存。
-
SHR 是共享内存的大小,比如与其他进程共同使用的共享内存、加载的动态链接库以及 程序的代码段等。
-
S:进程状态 (R运行状态 S睡眠状态 D不可中断状态 T跟踪/停止 Z僵尸进程)
-
%CPU:CPU 使用率
-
%MEM:进程使用武力内存占系统总内存的百分比
-
TIME+:上次启动后至今的总运行时间
-
COMMAND:命令名or命令行
在查看 top 输出时,还要注意两点:
第一,虚拟内存通常并不会全部分配物理内存。从上面的输出,可以发现每个进程的虚拟内存都比常驻内存大得多。
第二,共享内存 SHR 并不一定是共享的,比方说,程序的代码段、非共享的动态链接库, 也都算在 SHR 里。当然,SHR 也包括了进程间真正共享的内存。所以在计算多个进程的内存使用时,不要把所有进程的 SHR 直接相加得出结果。
2.2.缓存与缓冲区命中率
缓存
缓存是 Buffers 和 Cache 两部分的总和 , Buffers 和 Cache 的设计目的,是为了提升系统的 I/O 性能。它们利用内存,充当起慢速磁盘与快速 CPU 之间的桥梁,可以加速 I/O 的访问速度。Buffers 和 Cache 分别缓存的是对磁盘和文件系统的读写数据。
执行free命令
[root@centos7-2 ~]# free total used free shared buff/cache available Mem: 999720 542500 291348 6876 165872 290028 Swap: 2097148 0 2097148
字面意思,Buffers 是缓存区,Cache 是缓存,两者都是数据在内存中的临时存储
Buffers 和 Cache 的区别
通过执行 man free 来查看内存中 Buffers 和 Cache 的概念。
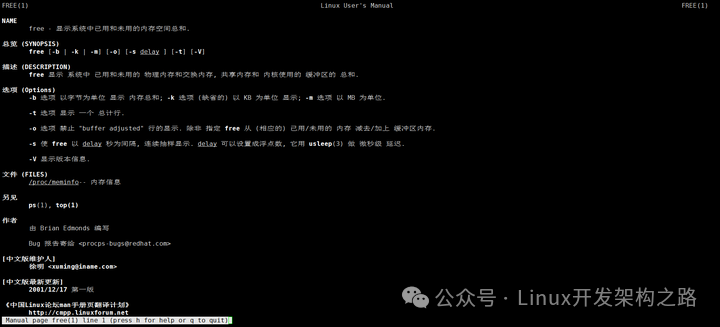
执行上面的命令,可以从帮助手册中看到 buwer 和 cache 说明
-
Buffers:内核缓冲区用到的内存,对应的是 /proc/meminfo 中的 Buffers 值
-
Cache:内核页缓存和 Slab 用到的内存,对应的是 /proc/meminfo 中的 Cached 与 Slab 之和
所以可以通过下面说的 proc 文件系统来确认它们的含义
proc 文件系统
-
/proc 是 Linux 内核提供的一种特殊文件系统,是用户跟内核交互的接口。比方说,用户可以从 /proc 中查询内核的运行状态和配置选项, 查询进程的运行状态、统计数据等,也可以通过 /proc 来修改内核的配置
-
proc 文件系统同时也是很多性能工具的最终数据来源
查看帮助文档了解Buffers和Cache
[root@centos7-2 ~]# man proc 没有 proc 的手册页条目 #如果没有man-pages ,不能执行 man proc ,如果系统中有man-pages,这步可以省略 [root@centos7-2 ~]# yum install -y man-pages ..... [root@centos7-2 ~]# man proc .... Buffers %lu Relatively temporary storage for raw disk blocks that shouldn't get tremendously large (20MB or so). Cached %lu In-memory cache for files read from the disk (the page cache). Doesn't include SwapCached.
Buffers
-
对原始磁盘块的临时存储,也就是用来缓存磁盘的数据,通常不会特别大 (20MB 左右)
-
内核就可以把分散的写集中起来,统一优化磁盘的写入,比如,可以把多次小的写合并成单次大的写等等
Cached
-
从磁盘读取文件的页缓存,也就是用来缓存从文件读取的数据
-
下次访问这些文件数据时,就可以直接从内存中快速获取,而不需要再次访问缓慢的磁盘。
小结:
-
Buffers 既可以用作将要写入磁盘数据的缓存,也可以用作从磁盘读取数据的缓存
-
Cache 既可以用作从文件读取数据的页缓存,也可以用作写文件的页缓存
-
Buffers是对磁盘数据的缓存,而 Cache 是文件数据的缓存,它们既会用在读请求中,也会用在写请求
缓冲命中率
1.什么是缓存命中率
缓存命中率,是指直接通过缓存获取数据的请求次数,占所有数据请求次数的百分比。
命中率越高,表示使用缓存带来的收益越高,应用程序的性能也就越好。
实际上,缓存是现在所有高并发系统必需的核心模块,主要作用就是把经常访问的数据,提前读入到内存中。这样,下次访问时就可以直接从内存读取数据,而不需要经过硬盘,从而加快应用程序的响应速度。
查看系统缓存命中情况的工具:
-
cachestat 提供了整个操作系统缓存的读写命中情况。
-
cachetop 提供了每个进程的缓存命中情况。
cachestat 的运行界面,以 1 秒的时间间隔,输出了 3 组缓存统计数据:
$ cachestat 1 3 TOTAL MISSES HITS DIRTIES BUFFERS_MB CACHED_MB 2 0 2 1 17 279 2 0 2 1 17 279 2 0 2 1 17 279
可以看到,cachestat 的输出其实是一个表格。每行代表一组数据,而每一列代表不同的缓存统计指标。这些指标从左到右依次表示:
-
TOTAL ,表示总的 I/O 次数;
-
MISSES ,表示缓存未命中的次数;
-
HITS ,表示缓存命中的次数;
-
DIRTIES, 表示新增到缓存中的脏页数;
-
BUFFERS_MB 表示 Buwers 的大小,以 MB 为单位;
-
CACHED_MB 表示 Cache 的大小,以 MB 为单位。
cachetop 的运行界面:
$ cachetop 11:58:50 Buffers MB: 258 / Cached MB: 347 / Sort: HITS / Order: ascending PID UID CMD HITS MISSES DIRTIES READ_HIT% WRITE_HIT% 13029 root python 1 0 0 100.0% 0.0%
它的输出跟 top 类似,默认按照缓存的命中次数(HITS)排序,展示了每个进程的缓存命中情况。具体到每一个指标,这里的 HITS、MISSES 和 DIRTIES ,跟 cachestat 里的含义一样,分别代表间隔时间内的缓存命中次数、未命中次数以及新增到缓存中的脏页数。
而 READ_HIT 和 WRITE_HIT ,分别表示 读 和 写 的缓存命中率。
3.性能剖析
3.1.内存性能指标
首先,最容易想到的是系统内存使用情况 ,比如已用内存、剩余内存、共享内存、可用内存、缓存和缓冲区的用量等。
-
已用内存和剩余内存很容易理解,就是已经使用和还未使用的内存。
-
共享内存是通过 tmpfs (内存的文件系统 )实现的,所以它的大小也就是 tmpfs 使用的内存大小。tmpfs 其实也是一种特殊的缓存。
-
可用内存是新进程可以使用的最大内存,它包括剩余内存和可回收缓存。
-
缓存包括两部分,一部分是磁盘读取文件的页缓存,用来缓存从磁盘读取的数据,可以加快以后再次访问的速度。另一部分,则是 Slab 分配器中的可回收内存。
-
缓冲区是对原始磁盘块的临时存储,用来缓存将要写入磁盘的数据。这样,内核就可以把分散的写集中起来,统一优化磁盘写入。
第二类很容易想到的,应该是进程内存使用情况 ,比如进程的虚拟内存、常驻内存、共享内存以及 Swap 内存等。
-
虚拟内存,包括了进程代码段、数据段、共享内存、已经申请的堆内存和已经换出的内存等。这里要注意,已经申请的内存,即使还没有分配物理内存,也算作虚拟内存。
-
常驻内存是进程实际使用的物理内存,不过,它不包括 Swap 和共享内存。
-
共享内存,既包括与其他进程共同使用的真实的共享内存,还包括了加载的动态链接库以及程序的代码段等 Swap 内存,是指通过 Swap 换出到磁盘的内存。
第三类 缺页异常 ,系统调用内存分配请求后,并不会立刻为其分配物理内存,而是在请求首次访问时,通过缺页异常来分配。缺页异常又分为下面两种场景。
-
可以直接从物理内存中分配时,被称为次缺页异常。
-
需要磁盘 I/O 介入(比如 Swap)时,被称为主缺页异常。
第四类重要指标就是 Swap 的使用情况 ,比如 Swap 的已用空间、剩余空间、换入速度和换出速度等。
-
已用空间和剩余空间很好理解,就是字面上的意思,已经使用和没有使用的内存空间。
-
换入和换出速度,则表示每秒钟换入和换出内存的大小。
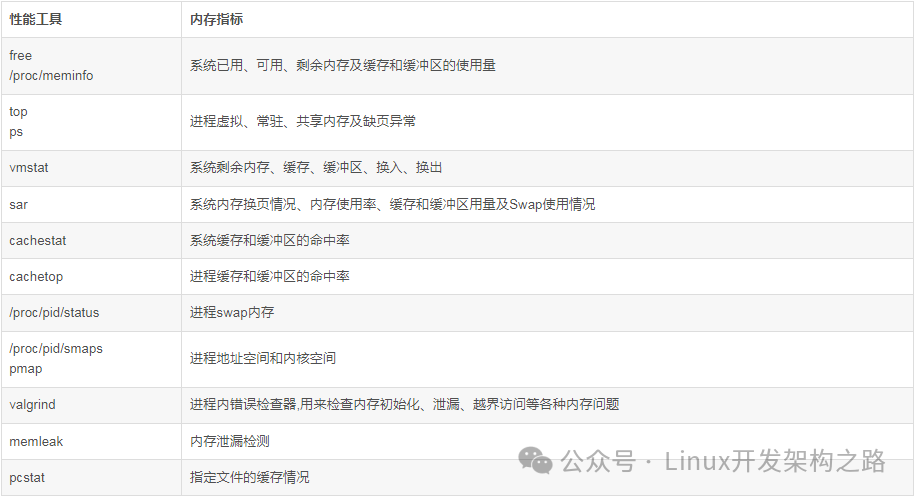
4.调优工具
4.1. 根据内存指标

4.2.性能工具出发
5.内存调优策略
常见的优化思路有这么几种。
-
最好禁止 Swap。如果必须开启 Swap,降低 swappiness 的值,减少内存回收时 Swap 的使用倾向。
-
减少内存的动态分配。比如,可以使用内存池、大页(HugePage)等。尽量使用缓存和缓冲区来
-
访问数据。比如,可以使用堆栈明确声明内存空间,来存储需要缓存的数据;或者用Redis 这类的外部缓存组件,优化数据的访问。
-
使用 cgroups 等方式限制进程的内存使用情况。这样,可以确保系统内存不会被异常进程耗尽。
-
通过 /proc/pid/oom_adj ,调整核心应用的 oom_score。这样,可以保证即使内存紧张,核心应用也不会被 OOM杀死。
 0
0







