
1、结构光(Structure Light)
结构光的代表应用产品就是PrimeSense公司为大名鼎鼎的微软家XBOX 360所做的Kinect一代了。
这种技术的基本原理是,加载一个激光投射器,在激光投射器外面放一个刻有特定图样的光栅,激光通过光栅进行投射成像时会发生折射,从而使得激光最终在物体表面上的落点产生位移。当物体距离激光投射器比较近的时候,折射而产生的位移就较小;当物体距离较远时,折射而产生的位移也就会相应的变大。这时使用一个摄像头来检测采集投射到物体表面上的图样,通过图样的位移变化,就能用算法计算出物体的位置和深度信息,进而复原整个三维空间。
以Kinect一代的结构光技术来说,因为依赖于激光折射后产生的落点位移,所以在太近的距离上,折射导致的位移尚不明显,使用该技术就不能太精确的计算出深度信息,所以1米到4米是其最佳应用范围。
2、光飞时间(Time of Flight)
光飞时间是SoftKinetic公司所采用的技术,该公司为业界巨鳄Intel提供带手势识别功能的三维摄像头。同时,这一硬件技术也是微软新一代Kinect所使用的。
这种技术的基本原理是加载一个发光元件,发光元件发出的光子在碰到物体表面后会反射回来。使用一个特别的CMOS传感器来捕捉这些由发光元件发出、又从物体表面反射回来的光子,就能得到光子的飞行时间。根据光子飞行时间进而可以推算出光子飞行的距离,也就得到了物体的深度信息。
就计算上而言,光飞时间是三维手势识别中最简单的,不需要任何计算机视觉方面的计算。
3、多角成像(Multi-camera)
多角成像这一技术的代表产品是Leap Motion公司的同名产品和Usens公司的Fingo。
这种技术的基本原理是使用两个或者两个以上的摄像头同时摄取图像,就好像是人类用双眼、昆虫用多目复眼来观察世界,通过比对这些不同摄像头在同一时刻获得的图像的差别,使用算法来计算深度信息,从而多角三维成像。
在这里我们以两个摄像头成像来简单解释一下:
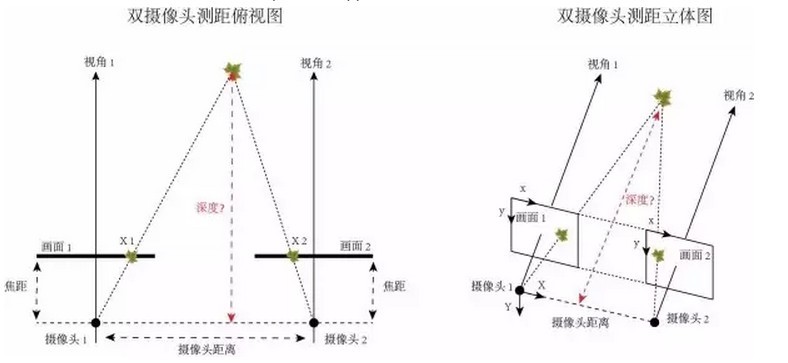
双摄像头测距是根据几何原理来计算深度信息的。使用两台摄像机对当前环境进行拍摄,得到两幅针对同一环境的不同视角照片,实际上就是模拟了人眼工作的原理。因为两台摄像机的各项参数以及它们之间相对位置的关系是已知的,只要找出相同物体(枫叶)在不同画面中的位置,我们就能通过算法计算出这个物体(枫叶)距离摄像头的深度了。
多角成像是三维手势识别技术中硬件要求最低,但同时是最难实现的。多角成像不需要任何额外的特殊设备,完全依赖于计算机视觉算法来匹配两张图片里的相同目标。相比于结构光或者光飞时间这两种技术成本高、功耗大的缺点,多角成像能提供“价廉物美”的三维手势识别效果。
TOF深度相机系统
系统描述
该系统利用单片CMOS技术直接探测3D信息,系统体积小巧,扫描速度快,可应用于游戏和消费电子、多媒体和广告、移动机器人、工厂自动化、安防监控、汽车辅助驾驶等领域。
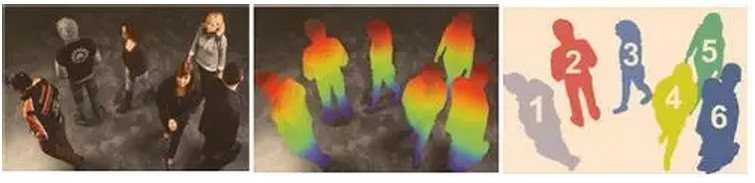
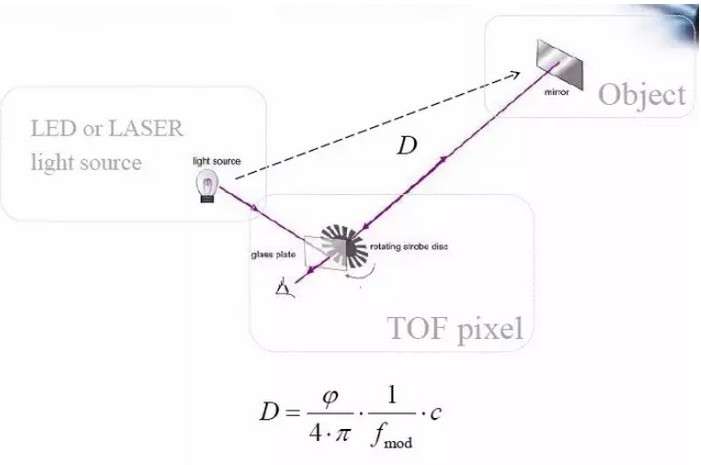
TOF是飞行时间(Time of Flight)技术的缩写,即传感器发出经调制的近红外光,遇物体后反射,传感器通过计算光线发射和反射时间差或相位差,来换算被拍摄景物的距离,以产生深度信息,此外再结合传统的相机拍摄,就能将物体的三维轮廓以不同颜色代表不同距离的地形图方式呈现出来。
 19.jpg920x158 17.2 KB
19.jpg920x158 17.2 KB 
要通过光线传播来测算距离,那么就需要一个能够发射光线的装置和接收光线的感应装置。大众使用了一个3D相机模块来发射脉冲光,再利用内置的感应器接收用户手部反射回的光线。然后,根据二者的时间差,处理芯片就可以构建出手部目前的位置和姿势。
大众手势识别技术中藏在换挡杆后方的ToF摄像头(红点位置)

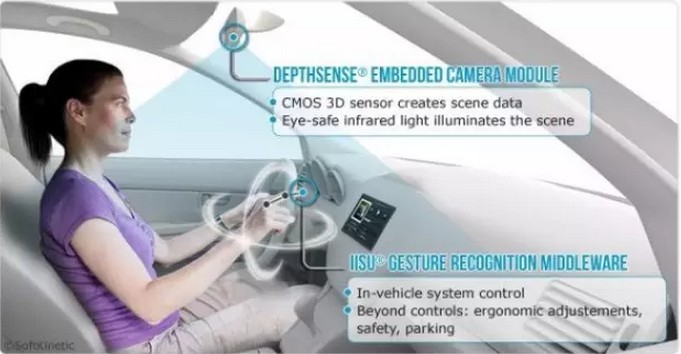
通过实时采集这些信息,中控系统就可以调用相应的数据库获得用户正在进行的动作。再根据预先定义的功能,就可以实现不同的操作。由于光的传播速度非常快,基于ToF技术的感光芯片需要飞秒级的快门来测量光飞行时间。这也是ToF技术难以普及的原因之一,这样的感光芯片成本过高。

来源: 硬件十万个为什么



 /4
/4 

