




是什么让Intel从业界巨头瞬间变身为牙膏厂呢?
近几年,Intel CPU的性能提升就像挤牙膏,所以叫,一年才提升那么一点,五年前的一代i5 i7,放在现在依然主流水平(5年来没多大进步?),于是网友们各种调侃。其实,Intel也不是一开始就是挤牙膏的节奏,譬如说:“扣肉“时代Intel就强调它的性能相比上代奔腾提升可以有40%。事实上,Intel并没有吹牛,与当时主流频率论相悖的高效能思维,把Intel从悬崖边中拉了回来。半导体届的蓝翔:AMD,其出产的挖掘机、推土机CPU,根本不是Intel对手。Intel心里也明白,有这么一个对手,得要好好规划,毕竟资本家就是利润最大化嘛。否则,按照原有的Tick-Tock速率,AMD很快就倒闭。缺乏竞争的Intel因为反托拉斯垄断法也会自身难保,从而面临诉讼、拆分,后果不堪设想。

一年又一年的马甲行为固然伤了不少A粉的心,一年又一年地挤牙膏行为何曾不也是让I粉们抓狂!?当然啦,Intel也不是一开始就是挤牙膏的德行,譬如说:Core时代Intel就强调它的性能相比上代奔腾提升可以有40%。
为了重新巩固CPU市场的统治地位。06年开始Intel玩起了Tick-Tock,Intel将升级的脚步就一直没有停止,Tick年改进制程工艺,Tock年升级微架构,一年一年的不断轮回,CPU性能也在一直不断的提升。尤其在Core 2到第二代Core i的时代,是Tick-Tock发展的黄金期。
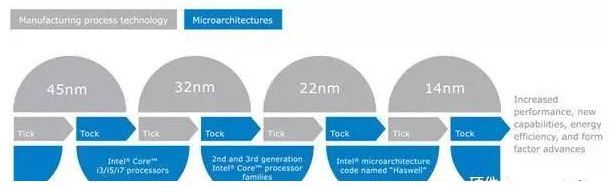
Tick-Tock到了Core i时代后逐渐失去了它的意义
Tick-Tock自从发展到第二代Core智能处理器后,性能增长的脚步减慢了。从Sandy Bridge到Ivy Bridge,再到Haswell,同频率性能提升的百分比只能用可怜的个位数百分比来形容,甚至到五代Broadwell出现了倒退现象。
摩尔定律失效?
大约十年前,英特尔宣布了著名的“嘀嗒”(Tick-Tock)战略模式。“嘀嗒”意为钟摆的一个周期,“嘀”代表芯片工艺提升、晶体管变小,而“嗒”代表工艺不变,芯片核心架构的升级。一个“嘀嗒”代表完整的芯片发展周期,耗时两年。
但是英特尔最近在公司文档中废止了“嘀嗒”的芯片发展周期,第三代Skylake架构处理器“Kaby Lake”CPU将在今年第三季度发布,彻底打破了“制程-架构”的钟摆节奏。从下一代10纳米制程CPU开始,英特尔会采用“制程-架构-优化”(PAO)的三步走战略。
由于受到CPU线程不断缩小的问题,英特尔从22纳米到14纳米都采用两步走,即所谓的“嘀嗒”战略。在“嗒”这一步,受限于工艺发展变缓,英特尔不缩小线宽,而是升级CPU核心架构。
但是在发展到14纳米制程时,英特尔已经“力不从心”,Skylake的发布时间比预料晚半年。当进入10纳米制程后,原本的芯片周期已经无法适应每年发布一代CPU,英特尔必须延长每一代制程的生命周期,也就是说每一代制程将沿用3年,共发布3代CPU。
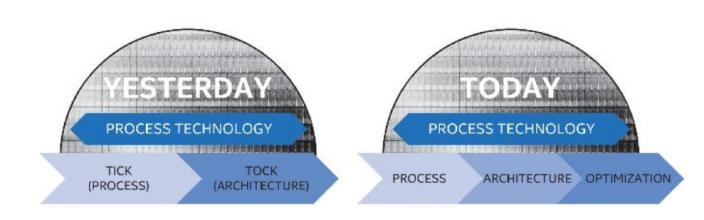
英特尔原本的“两步走”战略今后放缓到“三步走”
10纳米制程还将面临芯片制造的难题,因为10纳米仅仅相当于20个硅原子宽度。微软在文档中表示,优化芯片制程和架构将维持每年发布一代CPU的市场需求。
与竞争对手三星和台积电相比,英特尔在10纳米芯片技术上保持领先优势。英特尔相信未来芯片的制造会越来越困难,相比竞争对手的优势会愈加明显。然而,台积电此前曾表示,计划在2020年推出5纳米制程的芯片。
随着摩尔定律的失效,IBM公司已经开始研究纳米碳管和石墨烯材料的芯片。不过英特尔前CEO保罗?欧德宁CPU芯片基本材料在未来几十年内还会是硅。
NVIDIA:Intel为什么老挤牙膏?
在一篇第一财经日报采写的NVIDIA CEO黄仁勋人物专稿中,他这样说,“英伟达之所以行动迅速,是因为不考虑往后的兼容性。哪里快就走哪里,哪里不爽砍哪里。你看英特尔,要兼容各种老程序,所以新东西用起来就慢。”
不知道这能否作为技术层面一个很好的注解,当然,其中也暗含了NV对于Intel地位的觊觎。
目前,人工智能、深度学习正成为科技制高点,NV希望发挥GPU并行计算的优势,而Intel代表的x86阵营则依然坚守复杂指令集。
文章说“虽然英特尔处理器在执行复杂操作方面极其快速,但是它们在同时执行多个任务的时候就存在限制。而在这部分业务上,图形芯片的市场优势就体现出来了:它们可以用于同时执行大量而又简单琐碎的任务。”
形成鲜明对比的是,Intel“不务正业”的核显性能却节节高升。
曾经很早的时候,集成显卡给人的印象只是能提供图像输出,玩游戏什么的就别想了,然后过了些年,NVIDIA和AMD相继推出了高性能集显芯片组,也就是C61与690G这类经典产品,让大家见识到集显也是能玩大型游戏的,也就是这些高性能集显成就了当时AMD在低端平台的高性价比,随后这些iGP就被直接整合到CPU里面了,现在整合显卡的主板已经很稀有了。
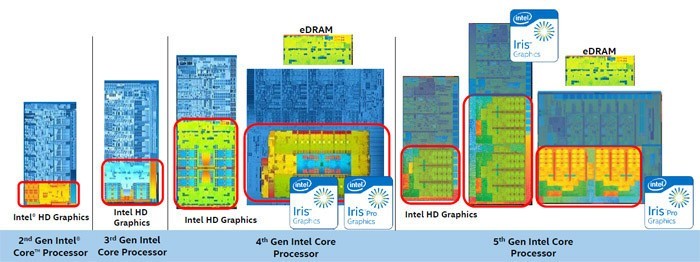
第二代到第五代酷睿处理器内部核显大小变化
AMD在收购ATI后,首先提出了CPU与GPU融合的概念,然而第一个把实际产品做出来的却是老对手Intel,早在2010年就推出了第一款整合GPU的CPU,随后Intel的核显每年都会随酷睿系列处理器一同升级一次,现在已经发展到了第六代,GPU的规模越长越大,以前是买CPU送GPU,现在都快成买GPU送CPU了。

从第一代酷睿处理器Clarkdale到今天的第六代酷睿处理器Skylake,可见整合核显的规模正在不断的增大,性能也是以倍数增加,而CPU每次升级都是以提高能耗比为主,说真的从Sandy Bridge到Skylake CPU的性能提升幅度并不算太突出,GPU性能反而成了每代处理器的性能提升重点,下面我们就来回顾一下Intel的核显进化历程。
首款整合GPU的CPU:Clarkdale

虽然说Intel的做法有点狡猾,但是2010年推出的Clarkdale处理器确实首款整合GPU的CPU,这款处理器由32nm制程CPU Die和45nm的GPU Die共同封装在一块PCB上组成,两颗芯片使用QPI总线相连,通俗点来讲Intel把CPU和北桥芯片用胶水粘在了一起。
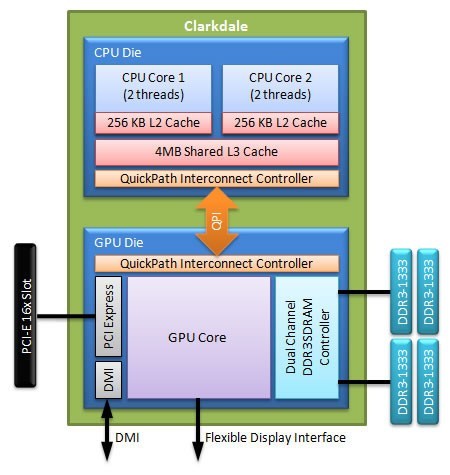
Clarkdale内核结构图,GPU Die上包含了PCI-E控制器和内存控制器,其实就是一个北桥芯片
Clarkdale系列处理器只有双核的型号,有Core i5-600和Core i3-500两个型号,在LGA 1156时代四核处理器是没有整合GPU的。
当时的Intel把Clarkdale上的GPU统称为“Intel HD Graphics”,这名字一直用到现在。而这个GPU其实就是G45上的X4500 HD的升级版,EU增加了两个达到了12个,核心频率最高可以到900MHz,支持Hierarchical Z(层次Z缓存算法)与Fast Z Clear(快速Z清除)技术,支持DX10、SM4.0,支持OpenGL 2.1,移动版处理器的GPU可以通过Turbo Boost动态调整频率,而桌面版不行。
真正的核显:Sandy Bridge
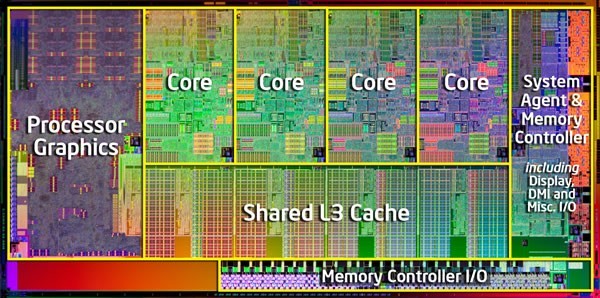
Sandy Bridge核心图
正在把CPU和GPU做到同一块芯片上的是在2011年上推出的Sandy Bridge架构处理器,CPU、GPU、内存控制器、PCI-E控制器全部整合到一个核心里面,它的最大改进在于三级缓存改用了环形总线设计,并且其核心、GFX以及显示/媒体控制器可共享L3高速缓存。

Sandy Bridge的GPU主要包含了指令流处理器、媒体处理器、多格式媒体解码器、执行单元、统一执行单元阵列、媒体取样器、纹理采样器以及指令缓冲等等,架构与上一代相比有了较大修改。
Sandy Bridge按照型号划分了标准版以及“K”系倍频解锁版本,标准版本GFX命名为HD Graphics 2000,而唯独K系列所拥有的GFX为等级更高的HD Graphics 3000,两者的区别是前者拥有6个EU,而后者则达到了12个,全面支持Turbo Boost动态调整频率,最高频率可达1350MHz,支持DX10.1、SM4.1,支持OpenGL 3.0,性能上HD Graphics 3000比上一代有了翻倍的增长。
此外这一代核显还增加了Quick Sync转码加速技术,利用内置的编码器可以支持MPEG2、VC1和H.264视频各种的硬件编码,Sandy Bridge所整合的图形核心已实现了视频解码和编码两部分的硬件加速功能,可为用户在视频转码时节省更多的时间。
迎来DX11时代:Ivy Bridge
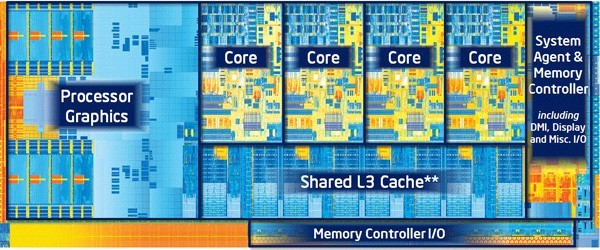
Ivy Bridge架构图
在Ivy Bridge上Intel针对核显的改进还是两个方向,首先是进一步提高GPU的性能,并且让其支持DX11,第二点则是继续提高核显的功能,多屏输出、高分辨率支持等。
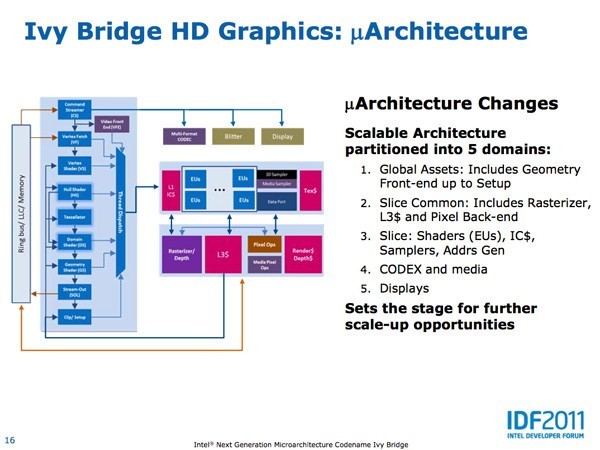
Ivy Bridge的GPU增强了几何前端、光栅化、像素后端处理、采样器、寻址单元的并行运算能力,每周期可以执行2个MAC操作,GPU可以直接读取L3缓存中的数据,图形单元新增两个可编程操作以及一个固定功能单元以支持曲面细分计算,并在解码与显示功能上做了升级。
同样的核显也分为两种,分别是有16个EU单元的HD 4000和6个EU单元的的HD 2500,“K”系列处理器用的是HD 4000而其他处理器用的是HD 2500,最高频率与SNB时代一样是1350MHz,支持DX11、SM5.0,支持OpenGL 3.2,性能上HD 4000比上一代的HD 3000提升是67%。
Ivy Bridge支持Quick Sync 2.0编码加速技术,与第一代相比,2.0版不仅速度更快,而且画质也会更高。视频输出方面也从原来的双屏上升到三屏输出,最大分辨率从原来的2560*1600上升到4k*4k级别。
“锐炬”登场:Haswell
Haswell架构图
Haswell采用的是Gen7.5核显,这一代开始Intel的核显开始了模块化、可扩展的设计,Haswell的显示核心采用两级EU团簇结构设计,上级的叫Slice,下级的叫Subslice,每个Subslice拥有10个EU,2组Subslice单元组成了1组Slice单元,这一代在GT1和GT2两个级别之上又诞生了GT3核心,从此Intel就走上了暴力堆砌核显规格的道路。
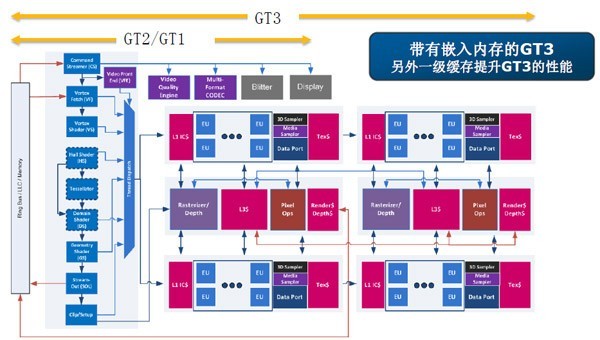
Haswell的GT1、GT2、GT3核显分别拥有10个、20个和40个EU单元,此外还有一个带嵌入式eDRAM的GT3e,核显集成了128MB eDRAM,位宽512bit,带宽可达64GB/s,这个嵌入式eDRAM是作为L4缓存存在的,可以同时提升CPU和GPU性能。
Intel的核显一直以来都用HD Graphics来命名,不过与NVIDIA的GeForce还有AMD的Radeon相比这个名字还是不够霸气,因此从Haswell处理器的核芯显卡开始,英特尔将引入新的名字“Iris”和“Iris Pro”,中文名为“锐炬”和“锐炬Pro”,分别对应GT3以及GT3e核显,具体型号则是Iris Graphics 5100和Iris Pro Graphics 5200。
这一代的桌面版酷睿处理器基本上都是使用GT2核显,型号是HD Graphics 4600/4400,后者只用在Core i3-41xx系列处理器上,只有16个EU,对非K系列处理器来核显性能是较上一代有大幅提升的,而真正需要高性能核显的也是Core i3那种级别的,高端处理器基本都是配个独显。
奔腾和赛扬处理器配的是GT1核显,而这一代最强的GT3e核显只出现在两款桌面级处理器上,就是Core i7-4770R和Core i5-4670R,然而这两个都不零售,是针对OEM市场的产品。
最强桌面核显:Broadwell
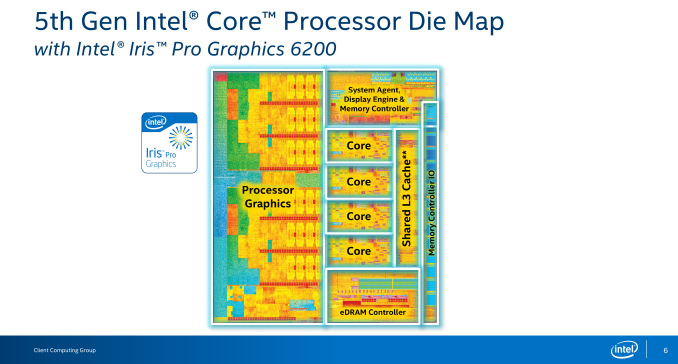
Broadwell-H内部结构
Broadwell主要都是面向移动市场,在桌面零售市场上其实就只有两个CPU,Core i7-5775C和Core i5-5675C,配备Intel目前最强的Iris Pro 6200核显,拥有128MB的eDRAM缓存,另外倍频无锁,可进行超频。
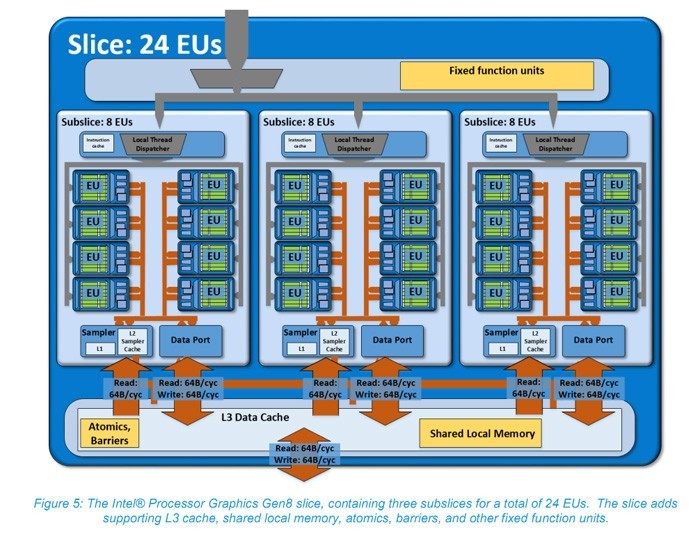
Broadwell上的Gen8 GPU架构示意图
Broadwell上使用的是Gen8图形核心,Intel重新设计了Subslice单元,每组的EU单元从之前的10个下降到了8个,在同样的采样器及调度器下这意味着每个EU单元的效率提升了,而弥补EU数量可以通过提升Subslice单元总数来完成,所以Broadwell的1组Slice单元有3组Subslice单元,EU单元总数是24个,Broadwell的GT1、GT2、GT3核显分别拥有12个、24个和48个EU单元。
桌面零售版那两个配备的Iris Pro 6200属于带eDRAM的GT3e核心,得益于核心规模的大幅提升,Core i7-5775C的核显性能较上一代Core i7-4790K提升了将近80%,而已由于现在的Skylake桌面版只有GT2核心,所以Broadwell架构的这两款处理器成为目前拥有最强核显的桌面级处理器,然而这两个处理器在国内根本没有正式上市,要买的话比较难找。
越堆越大的GPU:Skylake
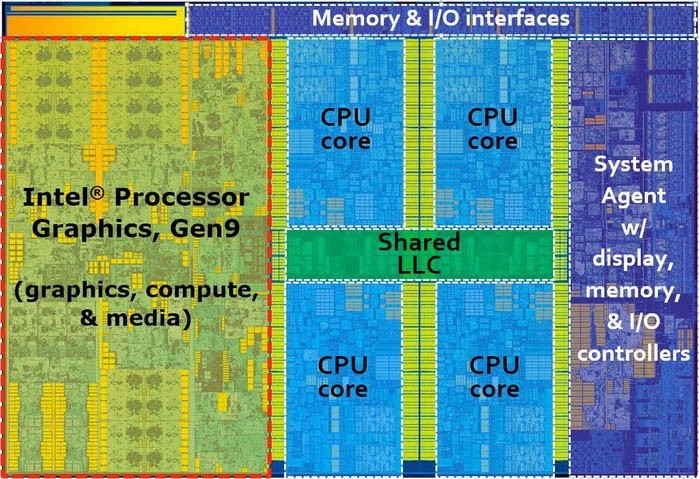
Skylake处理器核心
Skylake使用的Gen9代GPU其实与Gen8有很多地方都是相似的,每组Subslice单元依旧是24个EU,但是最多可以扩展到3组Slice单元,也就是说最多会配备72个EU单元,因此Skylake也多出GT4这个级别的核显。
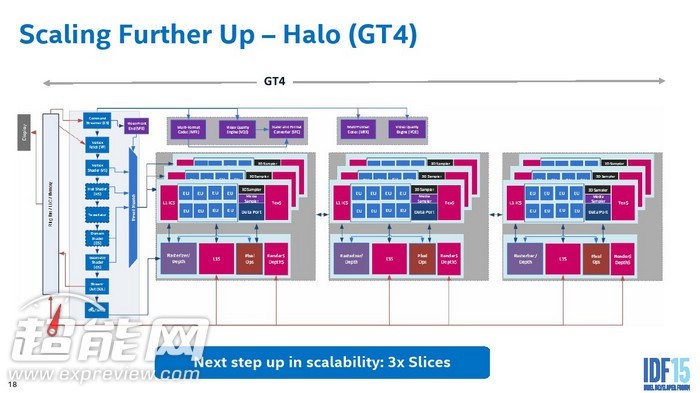
GT4核显可以支持3组Slice单元,72个EU单元
Skylake的Gen9架构支持DX12、OpenCL 2.x、OpenGL 5.x、Vulkan等图形规范,支持新的编译器堆栈,功耗范围从4W-65W+不等。此外,Gen9还支持HEVC/H.265、AVC、SVC、VP8、MJPG硬件加速,支持摄像头RAW架构。
多媒体方面,Gen9架构支持单一固定功能单元以降低功耗,Quick Sync转码单元也设计了固定功能的编码器以降低功耗、延迟。此外,Gen9的视频解码、转码加速还支持了HEVC(H.265)、VP8、MJPEG等标准。
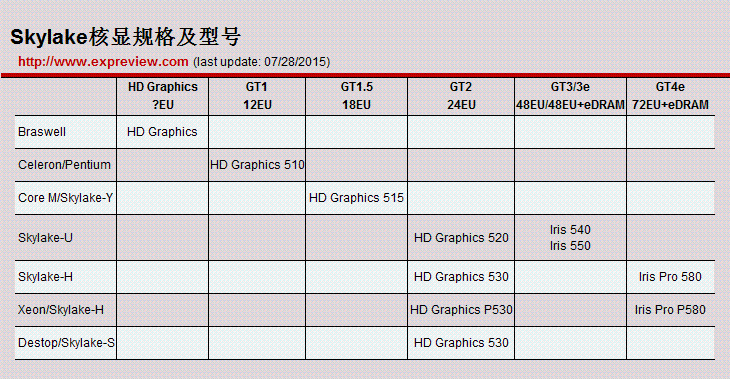
Skylake处理器上启用全新的核显命名
然而GT3/GT3e/GT4e这样的高性能核显只使用在移动版处理器上,桌面版的Skylake处理器基本上都是使用只有24EU的GT2,虽然较桌面版Haswell来说性能还是有所提升,但是幅度只有20%。另外还有两个“P”后续的处理器用的是GT1核显。
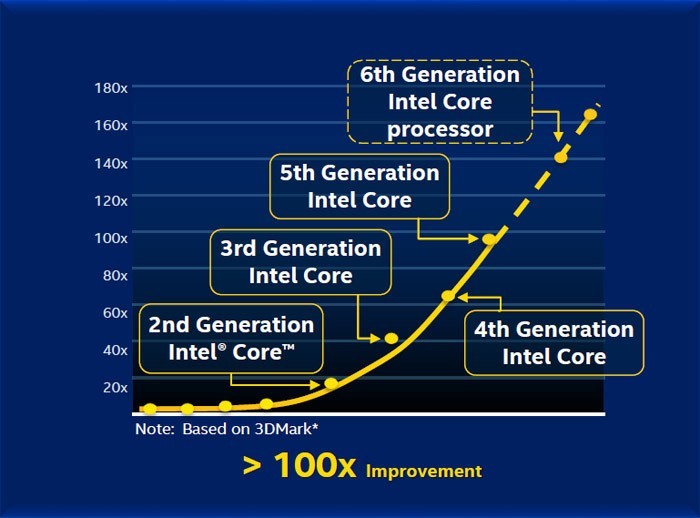
从Gen1到Gen9,Intel的图形核心性能有上百倍的提升
Intel这些年来在核显确实下了不少功夫,性能提升幅度相当的大,入门级显卡基本上都被核显赶尽杀绝了,而反观CPU,性能提升幅度就没那么明显了,降低功耗反而成了重点,低功耗的处理器造就了现在超级本和各种Windows平板的盛行,而这些年来移动设备都上高分辨率屏幕,这对核显又有了性能上的需求,市场的需求影响了Intel近年来的处理器改进方向,未来Intel CPU也是以提升核显性能并降低整体功耗为主。
Intel为什么不在提升性能上面发力,而在一心想做低功耗的原因
——强大的ARM
英特尔和ARM、Windows和Mac、安卓和iOS。一般而言,科技媒体都会打安全牌,并且迎合传统观点:英特尔最终必将战胜ARM、Windows会在与Mac的交锋中胜出,安卓最终也将力压iOS。
根据IDC公司数据,去年第四季度共计出货了近4亿台智能手机,几乎所有手机都采用了ARM架构处理器,其中80%的手机搭载安卓操作系统。
谷歌的安卓已经并将继续成为ARM的一个巨大的增长动力,特别是由于Android已经适应了包括机顶盒和车载信息娱乐系统在内的多种设备,目前,谷歌宣称Android活跃用户已经突破十亿。
正如相关人士之前所指出的那样,谷歌似乎有意将Android变成一个真正的通用操作系统,它将涵盖台式机、笔记本、平板电脑和智能手机等产品类别。对于大部分这些设备而言,都将采用ARM架构处理器,谷歌推广Android的举动不仅扩大了安卓的目标市场,也顺带提高了ARM的普及程度。
苹果阵营大约有6.8亿名iOS、tvOS和watchOS用户,他们使用的iPhone、iPad、AppleTV、苹果手表内部搭载的都是苹果公司基于ARM架构定制开发的处理器。苹果最近宣布,它的设备用量已经达到10亿台(包括Mac)。在一次采访中,一名苹果的高管指出,目前有7.82亿iCloud用户,少于设备总数,这也不足为奇,因为苹果用户往往拥有不止一台苹果设备。
总体上,安卓和iOS用户将超过16.8亿,这比微软通常宣称的Windows用户(大约15亿)还要多,这些用户的设备大部分运行ARM处理器。更重要的是,从发展态势上来看,ARM(安卓和iOS)的用户群近年来越来越大,而Windows用户则已经停滞多年。
智能手机的市场非常之大,但它仅占了2015年第四季度ARM处理器总出货量的10%左右,其它由电信交换机和一些服务器应用组成,但主要是在所谓的“嵌入式控制器”市场。由于ARM芯片的轻量化、低功耗、低成本优势,ARM在这个领域一直增长强劲。
随着ARM控制器结合了Wifi和蜂窝通信能力,嵌入式市场正快速转化为互联网市场。英特尔也对物联网市场给予厚望,但是ARM的成本优势将会像在智能手机领域一样,给予英特尔迎头痛击。
在转化到可联接的嵌入式设备的大趋势中,高通公司是一个主要的受益者,该公司正在其主营业务之外寻求邻近市场,物联网是其目标之一。高通公司在调制解调器技术以及将调制解调器和应用处理器集成在单颗芯片内的经验使它可以成为该行业的领导者。如果不考虑英特尔可能在AtomX3(代号为SoFIA)上集成了调制解调器的话,英特尔迄今为止尚没有将其任何一款调制解调器和处理器集成起来。之所以说可能,是因为目前尚不清楚调制解调器是否在处理器硅片上,还是只是和处理器在一个封装内。(来源:网络)


 /4
/4 

