


在C语言中,分支预测是一种关键的性能优化策略,旨在减少由于分支语句(如if、switch等)导致的预测错误,从而提高程序的执行效率。本文将通过一个经典案例来演示如何使用分支预测来优化程序性能,并对优化前后的性能进行对比。
原始代码
如果让你用C语言写一个函数,用来合并两个已经有序的数组为一个有序数组,升序。
可能很多朋友都会写成大概下面这个样子代码:
#include <stdio.h>
#include <sys/time.h>
void mergeSortedArrays(int *arr1, int size1, int *arr2, int size2, int *result) {
// 比较两个数组的元素并将它们合并到结果数组中
while (size1 > 0 && size2 > 0) {
if (*arr1 <= *arr2) {
*result++ = *arr1++;
size1--;
} else {
*result++ = *arr2++;
size2--;
}
}
// 如果arr1中还有剩余元素,将它们复制到结果数组中
while (size1 > 0) {
*result++ = *arr1++;
size1--;
}
// 如果arr2中还有剩余元素,将它们复制到结果数组中
while (size2 > 0) {
*result++ = *arr2++;
size2--;
}
}
int main() {
struct timeval start, end;
int i=0;
int arr1[] = {1, 3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27, 29};
int size1 = sizeof(arr1) / sizeof(arr1[0]);
int arr2[] = {2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30};
int size2 = sizeof(arr2) / sizeof(arr2[0]);
int mergedSize = size1 + size2;
int result[mergedSize];
// 记录函数执行前的时间
gettimeofday(&start, NULL);
// 合并两个已排序数组
mergeSortedArrays(arr1, size1, arr2, size2, result);
// 记录函数执行后的时间
gettimeofday(&end, NULL);
// 计算函数执行时间(以微秒为单位)
long seconds = end.tv_sec - start.tv_sec;
long micro_seconds = end.tv_usec - start.tv_usec;
double execution_time = seconds + micro_seconds / 1e6;
// 打印执行时间
printf("函数执行时间: %f 秒\n", execution_time);
// 输出合并且有序的数组
printf("合并且有序的数组: ");
for (i = 0; i < mergedSize; i++)
printf("%d ", result);
printf("\n");
return 0;
}
主函数里面构建两个人有序数组arr1和arr2,然后重点是使用mergeSortedArrays函数来合并两个数组,然后在合并函数的前后分别调用gettimeofday来计算合并函数的耗时,最后打印出合并函数耗时和合并后的数组结果。非常简单,重点是如下的合并函数mergeSortedArrays的代码实现。
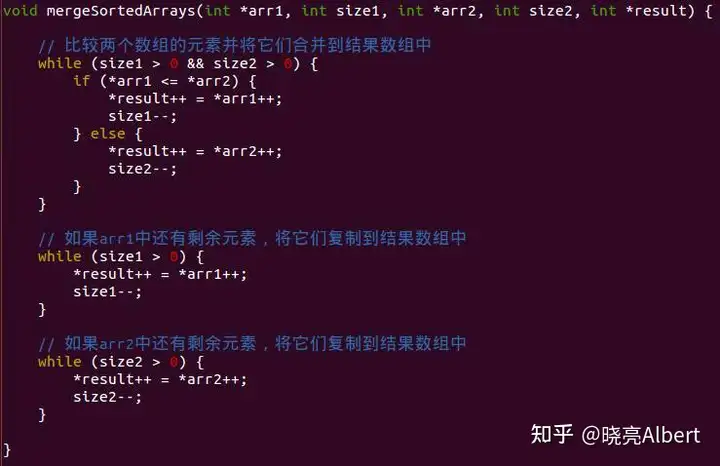
合并函数代码
下面我们来看看具体合并实现。函数讲2个被合并有序数组首地址和长度传进来,另外传进来一个保存最终合并后数组数据的数组首地址result。
1.函数中第一个while循环中,用size1和size2来记录两个被合并数组的剩余长度。只要两个数组中有一个遍历完了就退出循环。循环里面用分支语句if来逐个去比较两个数组成员,哪个成员的值较小就把他复制到result结果数组里去。
2.第二个while循环主要是看arr1数组中是否还有剩余元素,如果有就逐个复制到结果数组中。
3.第三个while循环主要是看arr2数组中是否还有剩余元素,如果有就逐个复制到结果数组中。
讲完了,很多朋友是不是觉得代码非常精简漂亮,效率很高啊,没问题,非常完美!
好那就运行一下吧,在ubuntu下面使用gcc并且加了-O2优化选型,优化代码,编译运行,结果如下:

原始代码运行结果
可以看到合并函数耗时是0.000002s,也就是2微秒,非常短,不错。
但是看看代码真的没办法优化这个代码了吗?如果我们来结合分支预测来考虑一下呢?
分支预测
我们来看一下整个函数中总共有4处条件判断。我们分别来看看四个分支条件的可预测性分别怎么样?
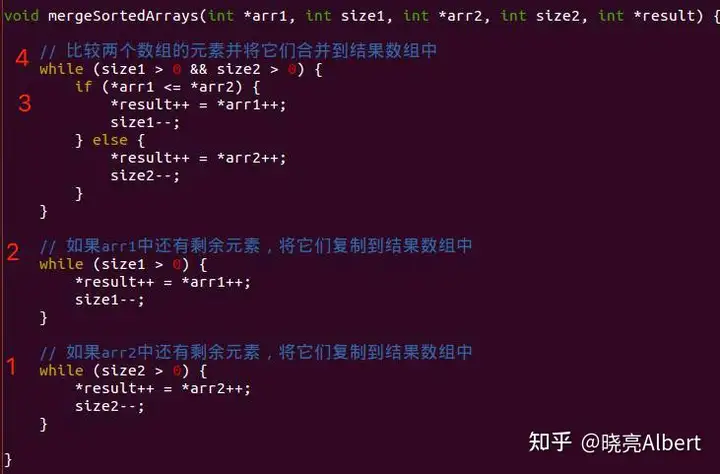
4个判断分支预测
第一处,也就是最后一个while条件判断,因为大多数情况下条件都会返回true,最后一次返回false,所以这个是可以预测的。
第二处,和第一处是一样的,也是可预测的。
第三处,是if判断,条件式判断两个数组的两个元素大小,这个大概一半是返回true,一半概率返回false,所以是不可预测的。
第四处,有事while条件判断,判断是否有至少有一个数组成员被复制完,这个大多数情况下是返回true的,所以也是可预测的。
总的结果如下表:
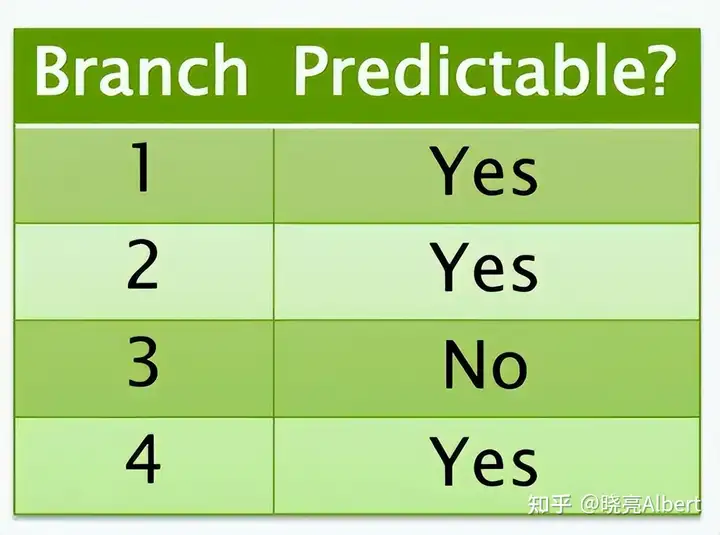
可预测否?
优化思路
那么既然第三处的if分支预测是不可预测的我们来否做点什么来优化一下?
我们知道,分支预测的目的是在程序执行时预测分支语句(如if语句、循环中的条件判断等)的走向,以便更好地执行预测分支的代码路径。
分支预测失败率表示在分支语句的预测中,实际执行的路径与预测的路径不一致的比例。高分支预测失败率表示预测不准确,导致程序执行了不必要的分支,从而浪费了处理器的时间。
一个优秀的分支预测器应该能够高效地识别程序中的分支模式,并根据历史执行情况进行准确的预测。如果分支预测准确性良好,那么程序能够更好地利用指令流水线和其他硬件特性,提高执行效率。相反,低分支预测准确性可能导致流水线中的指令冒险(pipeline stalls)和性能下降。
那么既然我们第三处这个if判断既然大半概率是会失败,那么我们是不是就不要用if分支语句来写这个代码,我们可以用位操作来实现这个if else分支代码,避免分支预测失败,从而优化代码效率。
优化代码
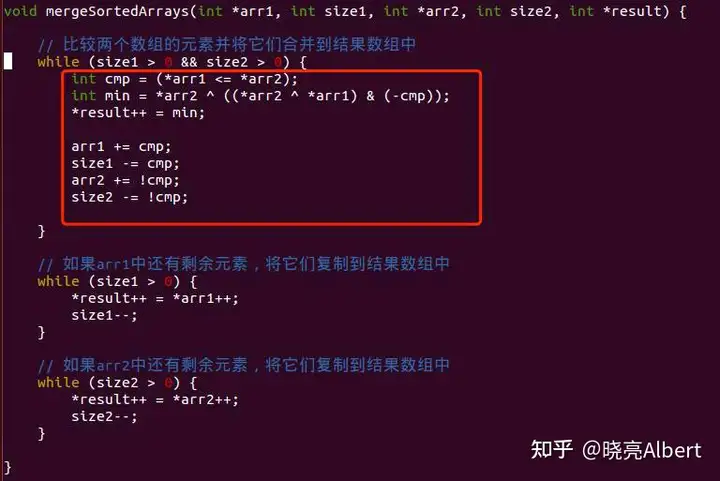
下面来看看如何用位操作代码代替ifelse分支功能吧。其它代码都不改,只是改一下合并函数第一个while循环里面代码:
void mergeSortedArrays(int *arr1, int size1, int *arr2, int size2, int *result) {
// 比较两个数组的元素并将它们合并到结果数组中
while (size1 > 0 && size2 > 0) {
int cmp = (*arr1 <= *arr2);
int min = *arr2 ^ ((*arr2 ^ *arr1) & (-cmp));
*result++ = min;
arr1 += cmp;
size1 -= cmp;
arr2 += !cmp;
size2 -= !cmp;
}
// 如果arr1中还有剩余元素,将它们复制到结果数组中
while (size1 > 0) {
*result++ = *arr1++;
size1--;
}
// 如果arr2中还有剩余元素,将它们复制到结果数组中
while (size2 > 0) {
*result++ = *arr2++;
size2--;
}
}
新代码
重点就是上图红框中的代码,首先用cmp来保存两个数组中元素的大小结果,要门是0,要门是1。接着借用异或(^)这个位操作巧妙拿到两个数中较小得的赋给min变量保存。我们来分析一下如何拿到两个数中较小的数的。
如果arr1小于arr2,那么cmp就是1,-cmp就是-1,-1其实就是补码形式存储,所有位全是1,-cmp与上arr1^arr2,那就是还是arr1^arr2,arr1^arr2其实就是两个数只要哪一位不同都会被置1,相当于不同位掩码。然后这个掩码再异或arr2其实就是将arr2中和arr1不同的位全部逆反。这样arr2是不是就变成arr1一样,所以min其实拿到就是arr1值。
如果arr1大于arr2,那么cmp是0,-cmp也是0,arr2异或0还是arr2。
这段代码最复杂部分就讲完了。
性能对比
下面我们来运行一下优化后代码,同上,还是在ubuntu下面使用gcc并且加了-O2优化选型,优化代码,编译运行,结果如下:

优化代码运行结果
可以看到合并函数耗时是0.000001秒,也就是1微秒,效率提升原来2倍。
需要指出的是,有些编译器自动优化后,效果不一定有提示。
提升这么点时间,有意义吗?真没有意义吗?如果说这个被合并的数组将来数据量非常大,比如说数组长度是1000000,那就是合并时间就可以缩短1秒了,那就非常厉害了。现在机器学习、大数据时代,数据大是很正常的,能缩短数据处理时间是很有价值的。
https://zhuanlan.zhihu.com/p/680936254



 /2
/2 

