
比如写服务端代码期间会去学习TDD,DDD,CQRS代码逻辑层的东西,学前端框架等度过第一个阶段。
后来会去学习大型互联网架构的解决方案,什么负载均衡,分库分表,数据一致性的解决方案,并发的处理及解决策略,降级,静态化,缓存一致性,异步MQ。
这些了解大部分处于填鸭式学习,比如只是去了解市面上常见的中间件及软件的使用,并没有涉及到底层原理或者实现方式上,换句话说知道的只是名词,还未深入,如果你对外人得意的说我会这么多东西之后,人家一句:你知道他的原理吗?为什么这样用?为什么不用别的代替?
在了解了市面上常见的解决方案或者中间件之后,下一阶段就是进入了原理了解期,这一期让自己深层次提升的有效方式是多问自己一句:为什么?然后把这个答案深刻理解之后印在脑子里,不要满足于我好像知道大概。
这一阶段的目的主要是深入去了解一些常见或是先进的中间件的实现原理,当然牛X的可以看其中的源码。
既然上面中间件主要应用场景是分布式场景。于是问一句:什么是分布式?
我印象看过wiki上的定义,具体的内容忘记了,大意是通过将任务单元分散在多个计算机节点上,节点之间通过消息通信。
所以可以归纳起来市面上常见的分布式场景:分布式计算,分布式存储,分布式通信。这样我们就可以归纳出一条去学习分布式基础的脑图,去了解内在原理,不满足于知道的程度。
很简单的道理,我通过一个礼拜学会的中间件或者框架,凭什么别人不能通过一个礼拜学会呢?反过来说也不用羡慕别人会用一些框架,如果只是在用上,他学了一个月会用,我为什么不能一个月学会呢?还是要锻炼自己的核心价值,比如基础算法,数据结构,设计模式,计算机组成原理,一切上层的中间件框架都是从这里开始是,同时强化自己的引申和联想能力,有没有更好的方式去解决。
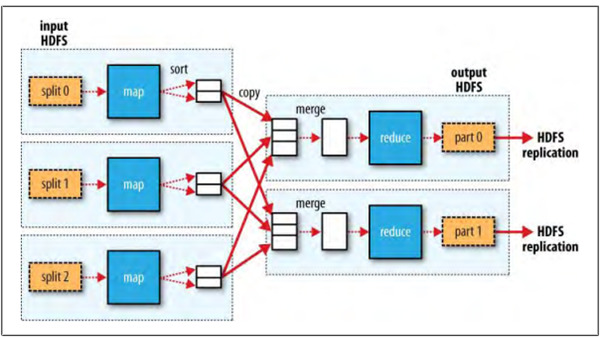
分布式计算,市面上较好的原理性文章可以看google的map/reduce论文,或者看一下map/reduce原理的文章去了解。然后自己去通过掌握的东西去模拟一个map/reduce的实现。
前几天做了一个导数的任务,会将历史数据导入es中,功能不难,但是数据量也是不小,把事情不是简单的做完,争取做好,借着这个机会可以实践一下,决定通过map/reduce的思想去实现。
map/reduce的思想主要是通过namenode做数据节点状态和分发管理,这个模块也可以叫做"元数据"。元数据这个概念在分布式概念中很重要,每个分布式中间件都会有类似的概念,任务节点是datanode。这里其实还可以引申出两个问题,状态的管理或者分发是namenode做记录好,还是datanode反馈好呢?
既然自己实现map/reduce,然后你会去考虑,namenode如何保证高可用,如何保证namenode和datanode之间的通信,压缩,同时会考虑将数据清洗任务交给datanode节点之后,是不是需要定制一套算法给到datanode去。
比如datanode处理的是查询功能,是不是可以自动转换成查询算法。如果datanode是排序功能,是不是可以自动切换到排序算法。或者考虑是通过IO将数据进行传导还是将计算方式传到,这里貌似有考虑了hadoop和spark的区别,一个通过传导数据会有IO延迟,传导计算单元则要快得多。同时还要考虑datanode节点崩掉的问题。
综上这些问题解决之后,一个简单的map/reduce的框架雏形就已经出来了,考虑到市面上常见的分布式框架,比如hadoop,dubbo等,元数据管理大部分通过zookeeper去实现,于是元数据也可以考虑通过zookeeper去实现,namenode做任务分发和备案。
多个datanode的分发,需要引入一个负载均衡的策略,一致性hash肯定是最好的方案,如果采用权重的负载均衡策略,如何保证单一datanode节点在一段时间内不会大量的获取任务,我才用的比较简单暴力的方式,就是对任务id对3求余这样可以保证求余为0的负载到权重较高的上面,同时不会让太多任务压倒权重高的上面,我知道这个方法肯定不是最好的,但是也没有花太多时间去做这个,但是说一下的目的是,我还是考虑了这个问题,炫技而已。
datanode对于消息的处理依赖,在自己维护的一个日志,日志的记录我们可以多考虑一下,市面上常见的日志记录方式我认为有三种:树形,哈希+链表,线性记录。
数据库索引是树形的,很大一部分由历史原因决定,比如nosql就为了避免这个问题。 哈希+链表的方式从hashmap这种基础的数据单元,到nosql的内存db都可以使用。 线性记录,这种kafka用的比较多。
通过这个数据结构可以引申出其他的问题,比如有人说我们最近用的elasticsearch,然后问他,为什么用es,为什么mysql不可以?好多人回答不上来,或者回答不在点上,要是我回答这个问题,我可能这样说:
elasticsearch底层索引的建立是通过lucene建立的,在对非结构化数据这种情况下,luncene的倒排序方式算法远远优于mysql,效率也更高,在扩容分区,备份问题上,es提供的解决方案较mysql更简单等。
了解lucene不要简单的了解这个库,争取从搜索引擎的角度去了解,推荐一本《这就是搜索引擎》,因为lucnen仅仅是建索引的一个库,但是早期称得上大数据,分布式的场景主要是搜索引擎,可以了解一下索引建立的算法,信息去噪,查找算法,最优记录的推荐,分词方式,或者自然语言处理这些,可以更系统一些去链接这些知识。
当然这些仅仅是实现自己的一个分布式计算框架的思考,具体还会涉及到容错,异常处理,线程池的拒绝策略,java的并发关键字等,这些有机会再讲。
今天主要说了实现一个分布式计算框架需要考虑的问题,分布式还有另外两大块,分布式存储和分布式通信,这些原理及机制以后再聊。
昵称:春哥叨客
来源:博客园



 /2
/2 

