
CPU、GPU、DSP:以现有技术解决新问题
在英伟达开发出针对人工智能的定制GPU,并坚持DGX-1 系统之后,Intel也不甘落后,在收购深度学习创业公司Nervana Systems之后,Intel也公布了用于深度学习的Xeon Phi家族新成员,在深度学习处理器领域开辟新战场。之后Intel和英伟达更是先后宣称自己的产品优于对方的产品,在舆论上打起来口水战。虽然现阶段短时间看还是GPU有优势——Intel的众核芯片也在一定程度上吸取了GPU的优势。不过,无论是针对人工智能的众核芯片还是定制版的GPU,本质上都不是专用处理器,实际上是拿现有的、相对成熟的架构和技术成果去应对新生的人工智能,并没有发生革命性的技术突破。
6月20日,中星微“数字多媒体芯片技术”国家重点实验室在京宣布,中国首款嵌入式NPU(神经网络处理器)芯片诞生,目前已应用于全球首款嵌入式视频处理芯片“星光智能一号”。不过,在经过仔细分析后,所谓“中国首款嵌入式神经网络处理器”很有可能是一款可以运行神经网络的DSP,而非真正意义的神经网络专用芯片。
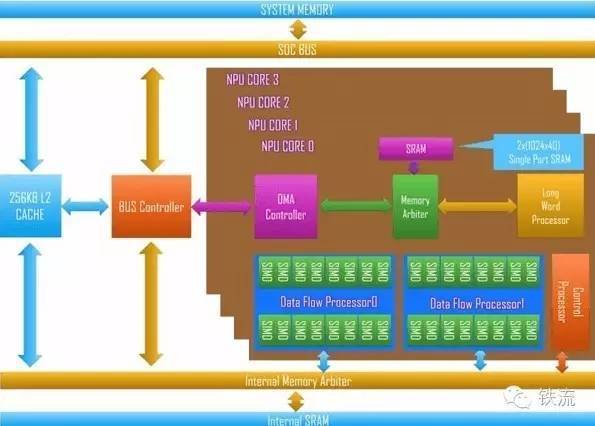
上图是星光智能一号发布的系统架构图,共包含四个NPU核,每个NPU核包含4个内核,每个内核有两个流处理器(DataflowProcessor),每个流处理器具有8个长位宽或16位宽的SIMD运算单元。每个NPU核的峰值性能为38Gops(16位定点)或者76Gops(8位定点)。除了多核流处理器本身用于完成卷积运算外,星光智能一号集成了一个超长指令字(VLIW)处理器用于完成神经网络中的超越函数等运算。另有256KB的L2Cache以及DMA模块用于大块数据的搬移。
从其低位宽的定点运算器推断,星光智能一号仅可支持神经网络正向运算,无法支持神经网络的训练。从片上存储结构看,星光智能一号基于传统的片上缓存(Cache),而非像最近流行的神经芯片或FPGA方案一样使用便签式存储。因此,在技术上看星光智能一号是典型的“旧瓶装新酒”方案,将传统的面向数字信号处理的DSP处理器架构用于处理神经网络,主要在运算器方面作了相应修改,例如低位宽和超越函数,而并非是“狭义的”神经网络专用处理器,如IBM的“真北”芯片。
因此,星光智能一号其实是DSP,而非NPU。其实,Cadence公司的TensilicaVision P5处理器、Synopsys公司的EV处理器和星光一号如出一辙,也是将传统的面向数字信号处理的DSP处理器架构用于处理神经网络,主要在运算器方面作了相应修改,例如低位宽和超越函数,而并非真正的NPU,能够适用于卷积神经网路(CNN),而对循环神经网络(RNN)和长短期记忆网络(LSTM)等处理语音和自然语言的网络有可能就无能为力了。
总之,Intel、英伟达、Synopsys公司、Cadence公司等都是在使用现有的比较成熟的技术去满足深度学习的需求,众核芯片和定制版GPU在本质上来说依旧是CPU和GPU,而并非专门针对深度学习的专业芯片,Synopsys公司和Cadence用传统SIMD/DSP架构来适配神经网络,和真正的NPU依然有一定差距。打一个比方,用众核芯片、GPU、DSP跑深度学习,就类似于用轿车去拉货,受轿车自身特点的限制,货物运输能力与真正大马力、高负载的货车有一定差距。同理,即便是因为技术相对更加成熟,Intel和英伟达的芯片在集成度和制造工艺上具有优势,但由于CPU、GPU、DSP并非针对深度学习的专业芯片,相对于专业芯片,其运行效率必然受到一定影响。
NPU:为深度学习而生的专业芯片
人工神经网络是一类模仿生物神经网络而构建的计算机算法的总称,由若干人工神经元结点互联而成。神经元之间通过突触两两连接,突触记录了神经元间联系的权值强弱。
每个神经元可抽象为一个激励函数,该函数的输入由与其相连的神经元的输出以及连接神经元的突触共同决定。为了表达特定的知识,使用者通常需要(通过某些特定的算法)调整人工神经网络中突触的取值、网络的拓扑结构等。该过程称为“学习”。在学习之后,人工神经网络可通过习得的知识来解决特定的问题。
由于深度学习的基本操作是神经元和突触的处理,而传统的处理器指令集(包括x86和ARM等)是为了进行通用计算发展起来的,其基本操作为算术操作(加减乘除)和逻辑操作(与或非),往往需要数百甚至上千条指令才能完成一个神经元的处理,深度学习的处理效率不高。因此谷歌甚至需要使用上万个x86 CPU核运行7天来训练一个识别猫脸的深度学习神经网络。因此,传统的通用处理器(包括x86和ARM芯片等)用于深度学习的处理效率不高,这时就必须去研发面向深度学习的专用处理器。
中国科学院计算技术研究所是国际上最早研究深度神经网络处理器的单位之一。2014年,中科院计算所和法国Inria合作发表的相关学术论文先后获得了计算机硬件领域顶级会议ASPLOS’14和MICRO’14的最佳论文奖。这也是亚洲首次在此领域顶级会议上获得最佳论文奖。
随后,国际计算机学会(Association for Computing Machinery)通讯也将这一系列工作列为计算机领域的研究焦点。这标志着我国在智能芯片领域已经进入了国际领先行列。此后中科院计算所独立研制了世界首个深度学习处理器芯片---寒武纪,发布了世界首个神经网络处理器指令集,后者于2016年被计算机体系结构领域顶级国际会议ISCA2016(International Symposiumon Computer Architecture)所接收,其评分排名所有近300篇投稿的第一名。
寒武纪相对于CPU和GPU究竟有哪些优势呢?寒武纪公司发布的Cambricon指令集直接面对大规模神经元和突触的处理,一条指令即可完成一组神经元的处理,并对神经元和突触数据在芯片上的传输提供了一系列专门的支持。寒武纪专用处理器面向深度学习应用专门定制了功能单元和片上存储层次,同时剔除了通用处理器中为支持多样化应用而加入的复杂逻辑(如动态流水线等),因此与CPU、GPU相比,神经网络专用处理器会有百倍以上的性能或能耗比差距。

(寒武纪板卡)
虽然寒武纪公司和中科院计算所尚未公布其商用产品,但我们可以从中科院计算所与法国Inria合作在2014年公开发表于ASPLOS2014学术会议的DianNao深度学习加速器架构看出一些端倪。DianNao为单核架构,主频为0.98GHz,峰值性能达每秒4520亿次神经网络基本运算,65nm工艺下功耗为0.485W,面积3.02mm^2。在若干代表性神经网络上的实验结果表明,DianNao的平均性能超过主流CPU核的100倍,但是面积和功耗仅为1/10,效能提升可达三个数量级;DianNao的平均性能与主流GPGPU相当,但面积和功耗仅为主流GPGPU百分之一量级。
在NPU上中国领先美国
由于IBM很不幸的点歪了科技树,这直接导致中国在NPU上暂时领先于美国。
真北本身的研究是基于脉冲神经网络(Spiking Neural Network,SNN)的,而寒武纪则一直面向的是机器学习类的神经网络,如MLP(多层感知机)、CNN(卷积神经网络)和DNN(深度神经网络)。
两种网络根本的不同在于网络中传递的信息的表示,前者(SNN)是通过脉冲的频率或者时间,后者则是突触连接的权值。目前在现有的测试集上,机器学习类的神经网络具有更高的精度(尤其是深度神经网络);前者则在精度上不能与之比拟。
精度是目前领域内很关心的非常重要的指标,比如近几年火热的ImageNet竞赛也是以识别精度为衡量标准的。正是因为曾经存在精度方面的差距,所以后来IBM的真北放弃了原来的路线图,也开始贴近机器学习类的神经网络,并采用了一些很曲折的方法来实现这一目标。
之前说过,真北本身是基于脉冲神经网络设计的,并且采用了逻辑时钟为1KHz这样的低频率来模拟毫秒级别生物上的脉冲,这也使得真北功耗很低(70mW),当然性能也比较有限。而寒武纪则是机器学习类的神经网络设计,运行时钟频率在GHz左右,能够极其快速且高效的处理网络计算。这使得寒武纪相对于真北具有性能上的优势。
相比之下,寒武纪系列的内部计算完全符合机器学习类神经网络(机器学习类网络本身也没有如同脉冲神经网络一样特别贴合生物神经元模型),通过调度在不同时刻计算不同的神经元从而完成整个神经网络的计算。这其中,涉及到处理器设计本身的一点是,通过不同参数的选取就能够完成不同规格(处理能力)的处理器实现。
笔者曾采访过杜子东博士(杜子东博士长期从事人工神经网络和脉冲神经网络处理器的研究工作,在处理器架构最好的三个国际顶级会议ISCA/MICRO/ASPLOS上发表过多篇论文,是中国计算机体系结构领域青年研究者中的翘楚),杜子东博士表示,“包括他们(IBM)在内,大家都认为他们(IBM)走错了路......”,并认为,“真北相对于寒武纪没有什么优势。硬要说有的话,那就是IBM的品牌优势和广告优势”。
结语
就深度学习处理器而言,美国可以凭借其在CPU和GPU上深厚的技术积累,并在芯片集成度和制造工艺水平占据绝对优势的情况下,开发出能用于深度学习,且性能不俗的众核芯片和GPGPU,而且这些美国IT巨头会利用他们巨大体量和市场推广、销售能力,大力推广用这些传统芯片来进行深度学习处理,在商业上能拔得头筹。
就现阶段而言,传统芯片厂商的CPU、GPU和DSP,其本质上也是对现有的技术进行微调。然而,由于传统CPU、GPU和DSP本质上并非以硬件神经元和突触为基本处理单元,相对于NPU在深度学习方面天生会有一定劣势,在芯片集成度和制造工艺水平相当的情况下,其表现必然逊色于NPU。
在NPU领域,由于IBM点歪了科技树,以及中科院在该领域具有前瞻性的开展了一系列科研工作,使中国能在目前处于优势地位。至于中国和美国的深度学习处理器,哪一款产品能在商业上取得成功,则很大程度上取决于技术以外的因素。就现在情况来看,大家基本处于同一起跑线,鹿死谁手,还未可知。
来源:铁流公众号



 /4
/4 

