
作者简介
邓世强,一线码农,从事通信行业,目前在一家通信公司担任内核工程师,日常喜欢钻研学习Linux内核知识。
1.实时系统的概念 1.1什么是实时操作系统
什么是实时操作系统?接触过嵌入式的小伙伴可能会知道,实时操作系统是指在嵌入式领域广泛应用的各类RTOS(Real Time Operating System)。其中最具代表性的有国外的μC/OS-III、FreeRTOS、Vxworks等,国内的代表有RT-Thread和LiteOS。
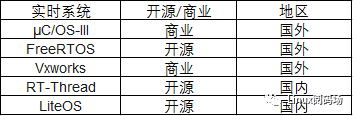
图1:常见的实时操作系统
在这些众多的RTOS系统里面既有开源的也有商业的,同时还有一些是行业专用的,比如enea公司推出的OSE系统就是通信行业早期的基站设备应用比较广泛的系统。无论是开源或是商业,这类系统都有一个最显著的特点,就是它们都具有很高的实时性。也是因为这个特点,它们都被集中应用在了嵌入式领域,特别是工控领域,例如工业制造控制、导弹飞机导航、电力设备监控等。历史上有很多著名的航空航天设备都使用到了实时的操作系统。比如登陆火星的凤凰号、好奇号火星探测器,它们所采用的操作系统就是美国WindRiver公司推出的Vxworks。那什么是系统的实时性呢?Linux系统在嵌入式领域也有大量使用,那Linux系统支不支持实时性呢?
1.2 Linux实时性、软实时和硬实时
实时性指的是一个操作系统能够在规定的时间点内完成指定的任务操作,一旦超过这个时间点会对整个系统带来不可估量的后果。与此相对的是一般操作系统,它更注重用户体验,系统偶尔卡顿不会给用户带来灾难性后果。实时性反映了一个系统行为控制的精准能力,具体体现在定时器的精准度高,中断响应及时以及系统的行为固定且可预估等。Linux系统最初是按照分时系统设计并推出的,再加上在历史版本中使用的调度算法目的是公平的分配和使用各种系统资源,保证CPU被各个进程公平的使用,所以早期并不支持实时性。但是在后来的2.6版本开始,加入了内核抢占的功能,使它的实时性得到了提升,在某种程度上具备了软实时的能力。软实时指的是系统对于时限要求并不是十分的严格,在一些情况下允许系统超限完成。举个例子,我们在PC机上使用鼠标操作,偶尔会出现卡顿延迟,这种情况除了让我们抓狂影响使用体验之外并不会给我们带来严重的影响,大家平时在使用电脑时遇到鼠标图标转圈圈同时界面不响应操作就是一个例子。再比如视频信号采集,偶尔丢失几个数据帧,并不会对视频最后的播放带来严重的画面缺失。但是硬实时就不一样,它对操作系统的行为有着严格的时限要求,超出时限往往会带来灾难性后果。比如在我们日常生活中使用的汽车都配备了安全气囊,汽车在发生激烈碰撞时可能会在0.2s内停下,那就要求气囊在0.02s内充气完毕并弹出,超出这个时间乘客可能就会面临生命危险。再比如导弹防御系统,当敌方导弹来袭时拦截系统必须做出100%的精准反应并计算出弹道轨迹进行拦截,稍有延迟就会造成拦截失败,这种后果是不可接受的。这就是硬实时系统和软实时系统的区别。但是由于Linux系统内核过于庞大且模块众多,内核中仍然有不少影响实时性的因素,比如使用大量自旋锁、中断禁止、时钟粒度等,使其距离us级别的控制精度还有很大的距离。但是也不能因此认定Linux系统今后就不能用于实时控制领域。
其实Linux内核一路发展过来,在历史的版本主线中仍然有很多技术公司或者大牛为了提升Linux系统的实时性而努力着,他们或是在某个版本上发布实时补丁,或是对内核进行一定程度上的改造,具体的代表有RTLinux、RTAI(Real-Time Application Interface)和Xenomai等。RTLinux全称叫做AReal-Time Linux,它由美国新墨西哥矿业及科技学院的V. Yodaiken开发。RTLinux采用了双内核的做法,可以说是开创了双内核法的先河。简单理解就是系统中存在两个内核,实时核和非实时核。底层硬件资源和实时的内核打交道绕开非实时核,来自硬件的中断源由实时核全面接管,把非实时的Linux内核当成实时核上的一个低优先级的进程来运行,通过这种方式确保实时核上的中断和任务得到优先响应,提升了实时性。Xenomai也借鉴了RTLinux的双内核做法,内部也有实时核和非实时核。但不同的是Xenomai在底层硬件和两个内核之间还加了一层硬件抽象层ADEOS(Adoptive Domain Environment for Operating System),实时核和非实时核作为硬件抽象层的两个域而存在,Xenomai内核属于实时域,Linux内核属于非实时域。ADEOS在系统的关键路径中对中断进行拦截,优先响应Xenomai实时域的中断,当没有实时任务和中断需要处理的时候才会轮到Linux内核执行。两者对比如下。
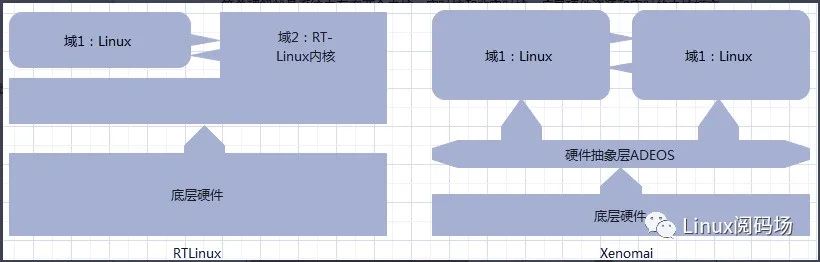
图2:RTLinux和Xenomai框架对比
由于版权、技术专利等因素,RTLinux已经不再更新。而Xenomai因为注重拓展性,可移植性和可维护性,对开发者相对友好,目前还在不断推出补丁,并且在社区活跃度很高,在工控领域也有不少成功应用的案例。这些基于Linux系统去改造从而提升实时性的系统的出现,使得Linux系统在发展过程中在实时性的研究上热度不减。甚至有不少人从Linux系统实时性研究入手,深入去学习Linux内核的调度机制、中断机制、定时器机制等,逐渐发展成自己的兴趣和爱好。从我们作为普通技术族的实力来说,可能不具备像国外的公司或者一些技术组织大改并发布实时Linux的能力。而想要提升系统实时性,有的是出于自身工作的需要,有的则是带着个人的兴趣爱好去钻研,那么如果想提升Linux内核的实时性,我们该怎么做呢?
2.1 实时性优化和时钟精度
知其然并知其所以然,知道影响实时性的因素才能很好的优化改造它。目前影响Linux内核实时性因素主要有时钟精度、系统中断、进程调度算法和内核可抢占性等。每一块都可以深入研究并做出相应的优化。首先是时钟精度,时钟就像是一个系统的脉搏,系统进程的调度切换是按照时钟节拍来进行的。目前Linux内核支持几种不同的系统节拍,可以在用户编译内核时配置。假设当前的系统节拍是100Hz,那么系统的时钟粒度就是10ms,如果提升到1000Hz,那么时钟粒度就是1ms,精度提升了10倍。
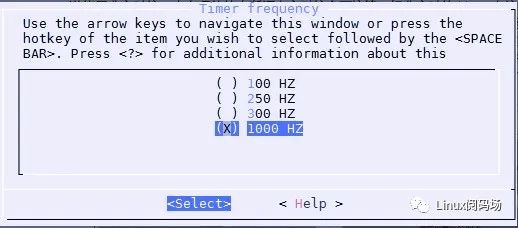
图3:编译内核系统节拍设置
上面这张图是CentOS7.6发行版系统默认的系统节拍设置。时钟精度的提升最直接的影响就是系统中的调度动作加快了,进程的响应也更为及时,但随着而来的是时钟中断频率的加快,这也加大了系统的开销和压力,因为会频繁的响应系统的时钟中断。在某些CPU消耗型的进程上会由于系统频繁的进行进程切换而导致CPU资源浪费,CPU的时间会浪费在进程切换上,因为从进程切换到实际被调度执行之间有一个时间差,叫做进程切换开销,所以好和坏我们还是需要根据自己的系统表现来看待。
2.2 中断
其次是中断。无论是RTOS还是Linux,硬件中断在系统当中的响应优先级永远是最高的。RTOS由于支持中断优先级,在实际使用过程中可以根据产品的实际情况针对不同的外设场景设置不同的优先级,且高优先级的中断可以抢占低优先级的中断,使得RTOS的中断响应非常迅速。Linux系统中的中断模块远比RTOS系统复杂得多。通常,Linux系统在进入一个中断时候,会禁止本地CPU的中断。在处理具体某一个中断的时候,由于禁止了本地CPU中断(NMI类型的中断除外),当有新的中断到来的时候只好挂起,只有当前的中断处理完才打开本地中断并响应新的中断。如果系统中存在大量不同类型的中断,势必会有一些中断被延迟得不到及时响应,这种延迟现象在单核CPU上表现尤为明显。针对这种情况,就要求我们在编写实际中断处理函数的时候,尽量在中断处理函数中不做复杂的操作,坚守中断处理函数“快进快出”的原则。比如只读取硬件寄存器等简单操作即可,剩下的数据处理的操作放到中断下半部中去执行,这就是所谓的“中断线程化”。传统上的中断下半部有软中断、tasklet、工作队列,它们的优先级也从高到低。软中断和tasklet工作在中断上下文不允许休眠它的优先级比工作队列高,工作队列工作在进程上下文允许休眠但是优先级最低,所以在实际编程开发中需要我们根据场景选择性的使用。如果是多核CPU,那么可以根据实际的中断情况把不同类型的中断迁移绑定到不同的CPU上,避免不同中断之间的干扰。下面以I.MX6DL硬件平台为例子介绍中断迁移的使用。首先,通过#cat /proc/interrupts指令查看系统的所有中断,如下图所示:
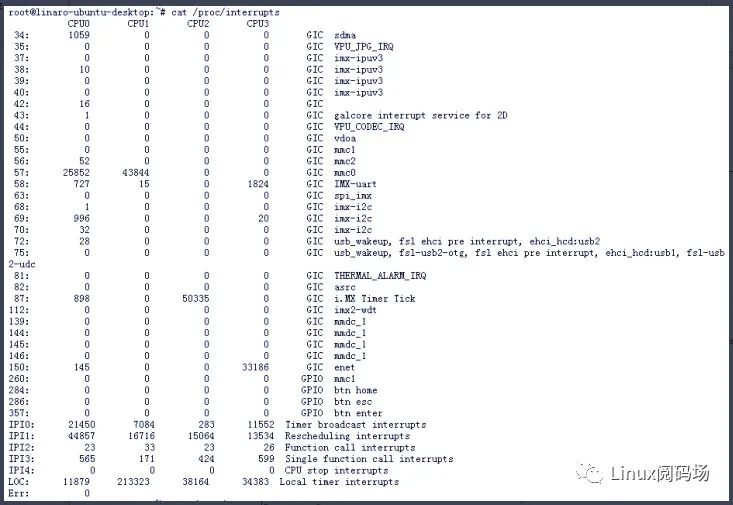
图4:绑定中断前的系统中断分布
从上面图中可以看出,当前的硬件平台一共有4颗CPU,其中IMX-uart和imx-i2c的中断集中发生在CPU0和CPU3,从第一列可以知道它们的中断号分别是58和69。接下来我们可以将IMX-uart中断全部迁移到CPU1上,让CPU0只响应imx-i2c中断。通过# echo "2" > /proc/irq/58/smp_affinity指令即可完成迁移。注意,这里的数字“2”表示CPU编号,它是从1开始。迁移后IMX-uart中断情况如下:
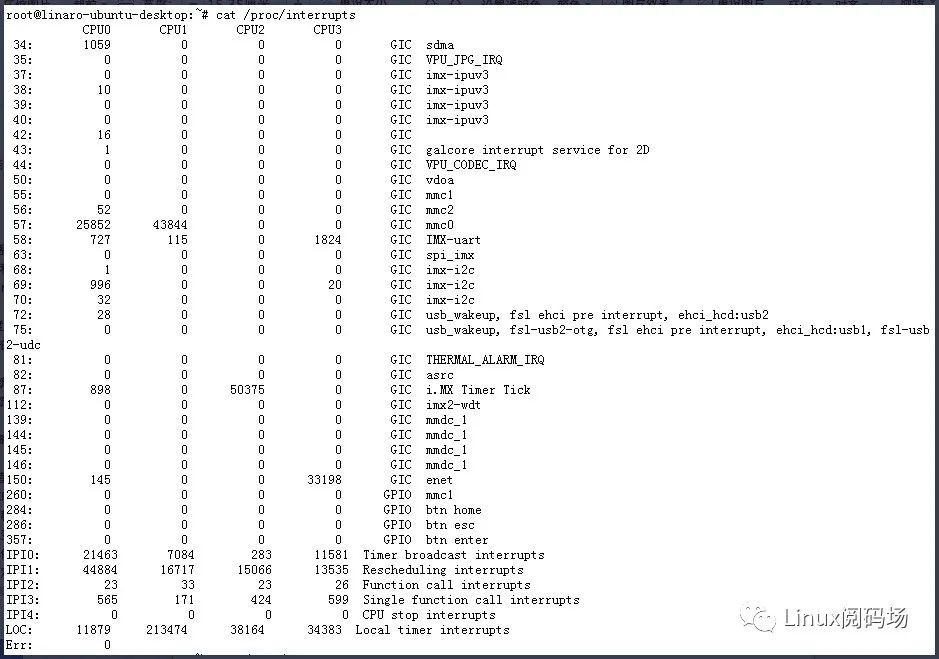
图5:绑定中断后的系统中断分布
从前后两张图对比可以看出,中断迁移前,IMX-uart在CPU3上的中断次数为1824次,在CPU0上中断次数为727次。中断迁移后,CPU0和CPU3不再响应IMX-uart中断,CPU1上IMX-uart中断次数由15次增加到了115次。我曾经在一个双核硬件平台上遇到过串口和SPI同时需要响应大量中断,它们互相影响导致中断响应不及时而出现数据丢失和输出不及时的情况,最终就是通过中断绑核解决的。中断绑核其实不能完全消除对实时性的影响,只能最大程度去降低中断对进程的影响,因为系统中NMI中断和本地时钟中断无法迁移和禁止。除了中断可以绑核,应用层的进程和线程也可以改变它们与CPU的亲和性,比如迁移到中断较少的核上,也能在一定程度上提升进程的实时性。
2.3进程调度算法
除了前面提到的时钟和中断外,还有一个影响实时性最大的因素就是操作系统的调度算法。Linux系统目前默认采用的是完全公平调度算法(CFS),它按照各个进程的权重来分配运行时间,在默认使用CFS的情况下,我们可以给有实时性需求的进程分配更高的优先级和权重,可以看做是通过赋予更高的优先级来获得更好的实时性。 Linux内核目前支持多种调度类,每一种调度类都是同一类型调度策略的集合,目前支持的调度类有:stop、deadline、realtime、CFS、idle。通常情况下进程都可选以上的几种调度类,他们的优先级依次由高到底排序,其中deadline调度类可选的调度策略有SCHED_DEADLINE,realtime调度类可选的调度策略有SCHED_FIFO和SCHED_RR,CFS可选的调度类有SCHED_NORMAI、SCHED_BATCH和SCHED_IDLE。在实际开发过程中,如果对时间有严格要求的实时进程可以选择deadline调度类,其他情况可以参考使用对应的调度策略,改变调度策略,是最直接的一种优化方式。其中deadline调度类的使用参考如下:

图6:deadline调度策略编程参考
2.4 内核其他限制
除了内核本身的调度算法的原因,Linux内核的调度模块当中还有其他限制因素。比如为了防止某个进程或某一个进程组长时间的占用CPU时间,Linux内核引入了一个“运行带宽”的概念,也就是说某一个进程或进程组使用CPU的总时间不能超过这个“带宽”阈值,默认值是0.95s。

图7:“运行带宽”默认值
实际开发过程中为了提高我们进程的实时性,需要进程长时间地占用CPU资源,我们可以把这个“运行带宽”给禁止掉。实际上不同的产品和使用场景也会有着不同的优化措施,如果设备的CPU核数比较多,我们可以从整体上去规划系统对于CPU的使用,大量的使用中断绑核和进程、线程绑核达到对CPU的独占使用。比如DPDK,它是Intel公司开发的一种高性能网络加速组件。在Linux内核中,传统的网络数据包的收发都是经过网卡驱动和内核协议栈,网卡驱动针对大数据包场景也做了大量的应对措施,但是从本质上来说,网络包的收发在内核中也还是依赖系统给我们实现好的软中断机制。而DPDK则是使用轮询代替了中断,它绕过了Linux内核的网络模块(驱动和协议栈),不需要频繁的进行数据的拷贝,使得用户空间可以直接看到硬件网卡的数据,这大大减小了数据传递路程上的开销。下面这张图就是使用轮询和DPDK独占CPU的一个例子。

图8:DPDK轮询独占CPU
再比如,irqbalance,它用于中断收集分配,会根据系统的负载情况自动进入性能模式和节能模式,会将中断平均分配到不同的CPU上去处理,特殊情况下我们需要禁止这个功能。还有其他比如禁止软锁、虚拟内存管理优化等。从上面可以看出,实时性优化的方法多种多样,甚至使用使用轮询代替了中断。但是关键还是在于我们要了解Linux内核模块的一些运行机制,和这些机制在实现上本身就存在的缺点,只有这样我们才能针对具体问题作出对应的优化措施。以上提到的这些方法只是从大的方向而且很浅显去分析和介绍Linux内核的实时性影响因素和对应的优化措施。总结起来有以下几点:
1. 中断优先级高,要减少中断对进程的影响;
2. 进程之间有优先级之分,要合理改变优先级;
3. 内核模块的实现机制限制,在特殊情况下使用轮训;
4. 提升系统节拍,提升定时精度;
5. 禁止irqbalance,防止进入节能或休眠模式;
2. 进程之间有优先级之分,要合理改变优先级;
3. 内核模块的实现机制限制,在特殊情况下使用轮训;
4. 提升系统节拍,提升定时精度;
5. 禁止irqbalance,防止进入节能或休眠模式;
还有其他更为深入的细节我们没有深入分析,比如Linux进程切换耗时,中断响应耗时、内存分配开销以及普通定时器精度和高精度定时器精度等,这些都是从细分的模块方向去研究并优化。进程的切换涉及到主调度器和周期调度器,它们都不可避免地涉及到定时器,目前Linux内核的高精度定时器也很难做到us级别,这也就决定了在调度的时间上也不是那么地准确,再加上内核中充斥着大量的自旋锁,而自旋锁的使用会关闭CPU的中断进而影响实时性,所以在开发过程中更加提高了对我们自身的水平要求。
前面列举的这些优化措施实施起来很简单,但对于我们自身来说更要理解为什么要这么做。深入去分析Linux内核的机制,实际的去阅读内核的模块源码,才会在实时性或者Linux内核的学习道路上收获更多。比如阅读内核源码才会知道tasklet和workqueue的应用场景的不同,尽管它们都是“中断下半部”之一,但是它们在内核当中执行的优先级还是有很大区别。只有阅读内核源码,才会知道tasklet和hrtimer也是基于软中断的,而且这个软中断也有优先级之分。也只有阅读内核源码,才会知道系统目前实现了多少种软中断,甚至我们自己也可以实现软中断获得实时性的提升,尽管Linux内核不建议我们这么做。除了阅读内核的源码,掌握调试跟踪内核的工具也必不可少,比如ftrace、trace-cmd、kernelshark、perf等。俗话说,工欲善其事必先利其器,熟练掌握这些工具的使用会让我们优化工作更高效。ftrace是一个很强大的调试工具,除了常用的函数跟踪器能让我们轻松知道一个函数的执行耗时之外,它强大的event机制,更是可以直接让我们在驱动或者内核中添加跟踪点,输出内核执行过程中的各类数据,让我们轻松洞察内核的执行过程。总之,实时性优化是一条漫长的道路,一路上也充满了各种未知,钻研越深越对它充满好奇,也越觉得Linux内核神奇。比如你可能会好奇在Linux内核中一个进程从被唤醒到真正去执行这个过程花了多长时间。又比如一个外部中断,从它被触发到真正走到用户注册的中断处理函数,这个过程又花了多长时间。只有自己亲自到设备上去调试,去尝试弄明白这些问题了才会发现Linux内核有趣的地方,也才会越走越充实。以上只是我自己在工作过程中积累的一点观点看法,如果读者面对Linux内核不知道从何处入手的话,个人建议不妨从实时性优化这个方向入手,逐渐深入。
本文由编辑推荐,原出处:https://www.eet-china.com/mp/a124017.html



 /2
/2 

