
硬核音频系列文章列表:
- 硬核音频系列(一)—— 声音信息的表示:基础概念扫盲,PCM 编码方式
- 硬核音频系列(二)—— 音频文件编解码格式:动手实现 adpcm 解码器
- 硬核音频系列(三)—— 线性淡入淡出:算法思路、实现与优化方法描述
在系列第二篇,会介绍一些关于音频数据存储、处理的内容,并回答上一篇末尾提出的两个问题:如何减小 PCM 格式数据的体积和管理这些数据。
音频数据的存储我们不能直接在硬盘上保存 PCM 格式裸数据,就好比超市货架上的食品需要处理过才能上架,一块带血有毛的生肉耷拉在顾客面前,可不是件令人愉悦的事情。把食材加工、打包并贴上标签,这样才是一个合格的商品,同理,音频数据也需要进行加工打包,最终作为一个个文件摆放在我们电脑中。
编码格式、编解码器与容器PCM 格式数据表示声音波形在某一时刻的真实值,能够被声卡和 DAC 直接「食用」。把这些 PCM 裸数据进行二次压缩编码,得到体积减小的音频数据,再附加一些属性信息(采样率位深通道数等),装进特制的容器中,成为可传播、处理、播放的单个音频文件。
在一个音频文件中,既有表示声音本身的音频数据(可以是 PCM 格式或经过二次编码),也有描述音频属性的一些元数据(Metadata),这类数据虽然不能被播放,却对播放起到重要辅助作用。对同一段声音使用不同编码格式编码,能得到不同的二进制音频数据,常见的编码格式有 PCM, MP3, AAC, FLAC 等。

按照编码过程中是否损失声音信息,编码格式分为有损编码和无损编码格式,PCM 格式是无损编码,而有损编码为了压缩数据大小,并没有完整记录声音数据。例如 MP3 编码丢弃某些人耳不敏感的频域,可大大降低文件体积,同时保证高音质。
编码后的音频数据不再表示波形采样值,因此不能直接输出播放,必须经过解码还原为最初的 PCM 形式,再发送给硬件播放。编解码器(codec)负责不同格式音频数据与 PCM 之间的编码和解码。各类编码格式数据,在解码后播放起来和 PCM 没有两样,PCM 是音频系统软硬件的桥梁。
无论是 PCM 还是压缩后的音频,都需要通过容器封装,得到最终音频文件。所谓的封装,无非就是加头添尾,增加额外描述性数据,便于上层进一步处理。描述数据的数据也称为元数据(metadata),音频容器包含了音频数据、音频参数(采样率、位深通道数)、文件参数(大小)等,将文件划分成许多块区域,不同的容器格式规定了各类数据组织方式(大小顺序和位置),下图是 WAV 容器格式内的数据排布方式:
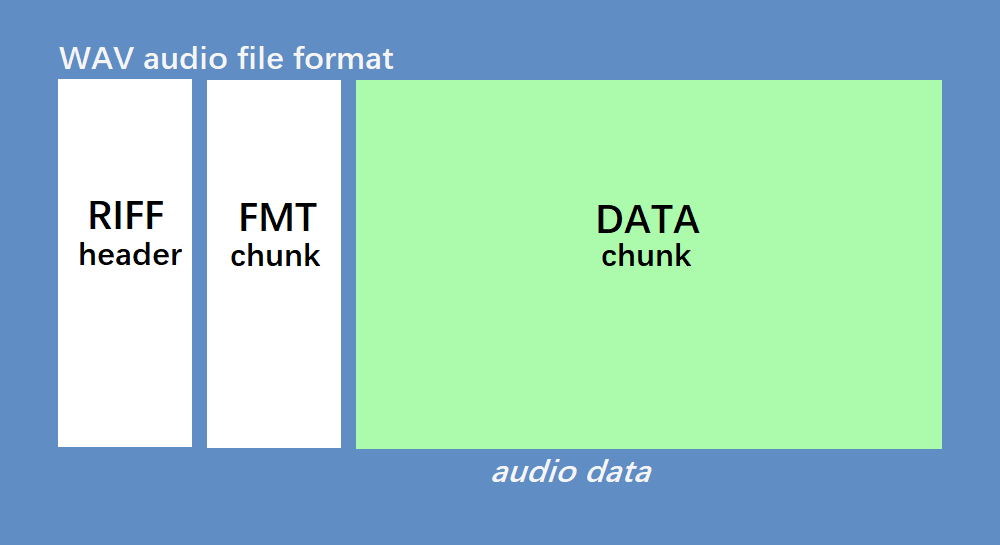
容器格式往往和文件后缀名对应,如 .wav、.m4a 等文件类型同时代表容器格式。
音频容器格式和编码格式是两个独立的概念,一种格式的音频数据能用多种容器封装,一种容器也能更换不同编码的数据。例如 MP3 编码数据可以用 WAV 或 MP3 容器封装,m4a 容器能封装 ALAC 或 AAC 两种编码,实际应用中要根据不同编码与容器特点,结合场景和系统情况选用搭配。
又比如大部分情况下 WAV 容器保存原始未压缩 PCM 格式,音质较好,但也有使用压缩编码的例外情况,因此 .wav 文件不一定是无损音质,还取决于其中使用的编码格式,如果使用 MP3 或者下文即将介绍的 ADPCM 编码,那还是属于有损的。
下面是一张不同音频格式的快速检索表:
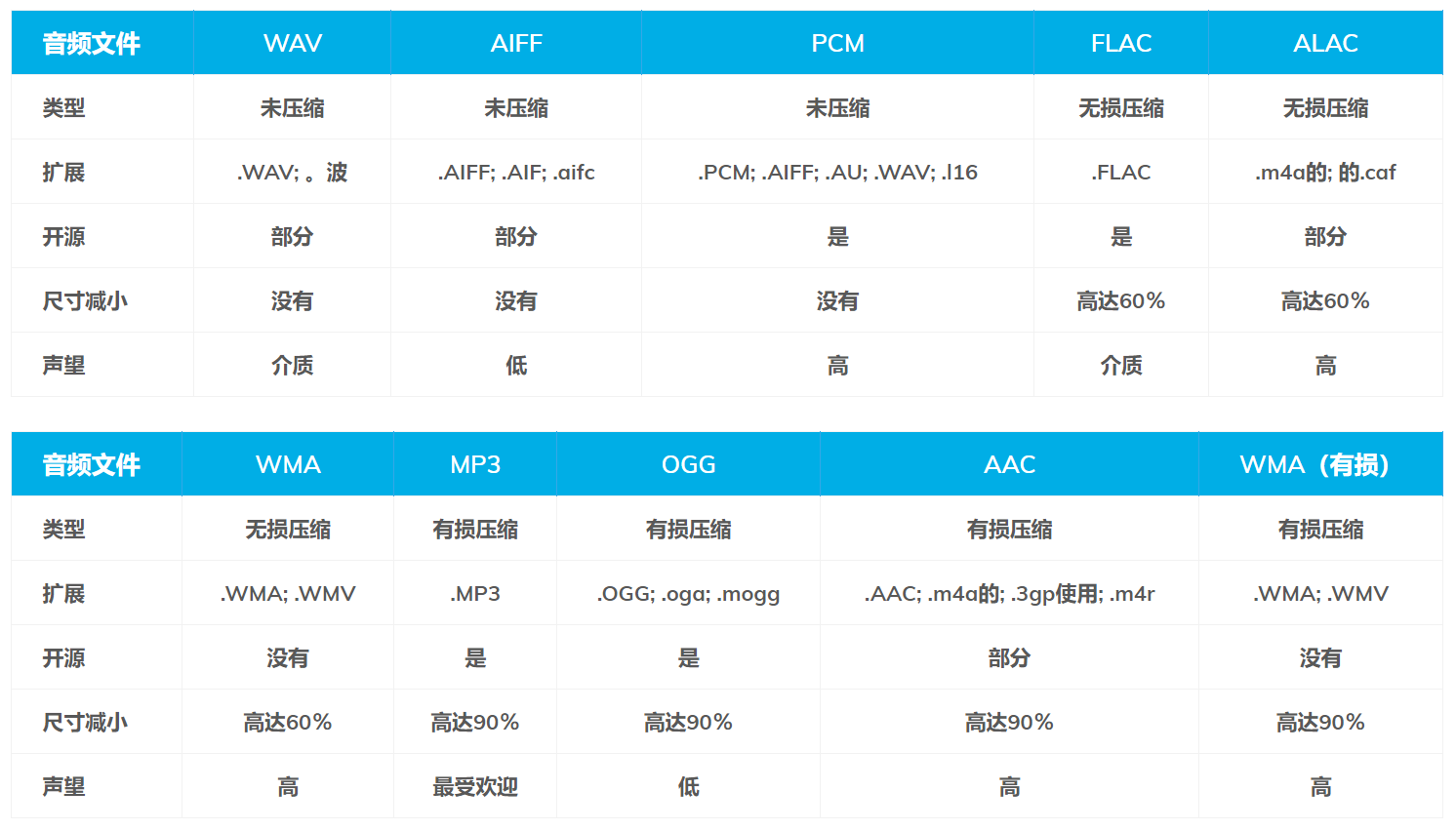
音频编码及文件容器是一个很庞大的知识领域,不同的标准下又有各种扩展和细分,限于篇幅,这里不做一一展开,有兴趣的读者可以看下这个维基词条:音频编码格式的比较 - 维基百科,自由的百科全书
音频压缩音频编码的出现很大程度上是为了压缩文件体积,大文件除了占用存储空间,对传输带宽也是一笔不小的消耗,这涉及到文件比特率的问题:音频越大,播放时在单位时间需读取的数据量也就越大,还是假设有一段 44.1k 采样率、16bit 位深的立体声 PCM 数据,播放 1 秒钟就需要 44100 × 2Byte × 2 = 172KB,意味着传输速率也必须达到 172KB/s,换算为码率就是 1376 kbps,对系统 IO 性能和数据可靠性都是不小的挑战。
如果事先对音频进行压缩编码,保存为 MP3 格式,能大幅度地降低音频数据量,同等参数下码率仅有 128kbps,传输起来要轻松的多。众多不同的音频压缩编码,采用的算法原理不尽相同,但有着同样的目的 —— 为了节约数据的存储和传输带宽。MP3 通过去除频域上人耳不敏感的部分减少数据量,包括霍夫曼编码、频谱重排列、IMDCT 变换等复杂过程,相比之下,ADPCM 编码格式就简单得多,解码器也更容易实现。
ADPCM 格式由于声音信号具有波形上的连续性,因此相邻两个采样值大小也非常接近,记录单个采样值通常需要 16bit,而记录前后两个采样点的差值(差分法),往往只需要 4bit,这便是 ADPCM 压缩编码的基本原理,因此通过 ADPCM 编码的音频文件,其大小只有 PCM 格式的四分之一。
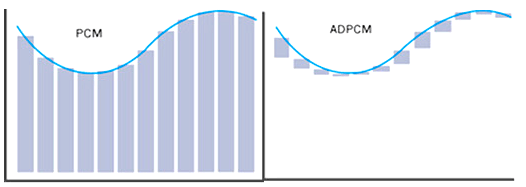
不仅如此,ADPCM 的智能之处在于,对于变化剧烈的波形,算法通过自适应机制,能自动改变差分值的度量粒度,即使是抖动较大的信号,也可以保证前后采样差值总能用固定的 4bit 表示。在 PCM 编码的基础上增加 「差分」和「自适应」的特性,便是 ADPCM(Adaptive Differential Pulse Code Modulation 自适应差分脉冲编码调制) 名称的由来。
当然,ADPCM 算法实现简单、压缩率高的同时,必然要付出音质损失的代价 —— ADPCM 格式文件的声音听起来会略为粗糙,被同样是有损压缩的 MP3 编码吊打,不过用于提示音、人声讲话等场合还是绰绰有余。
实现 ADPCM 解码器学习知识的一个好方法是动手实践,通过实际代码能加深对技术的理解,接下来将会介绍如何编写一个车 ADPCM 解码器 —— 将 ADPCM 数据还原为 PCM 格式,但在开始之前,要先选定一个 ADPCM 标准作为依据。是的,ADPCM 下面还分了好几类,有 YAMAHA 、Microsoft、IMA 等标准,不同的处理流程也会有细分的规范。下面选择 Microsoft 格式(MS ADPCM)作为我们实现解码器的标准,并参考 FFmpeg 的代码,开启「照抄模式」。
Microsoft ADPCM 标准有关 MS ADPCM 解码器的编程和实现,看懂这两个网页就够了:
- Microsoft ADPCM - MultimediaWiki
- FFmpeg: libavcodec/adpcm.c Source File
第一个页面是 MultimediaWiki 对 Microsoft ADPCM 的基本介绍、技术细节及实现解码方式的详细描述,理解这些内容有助于我们看代码,做到心中有数,至少不会一脸懵逼。下面解释一下其中比较关键的信息。
block 构成MS ADPCM 音频数据由许多 block(块)组成,每个块包含前言(preamble)和半字节序列(series of nibbles)两部分,preamble 包括一些自适应差分相关参数以及两个原始采样数据,半字节序列是编码后的 ADPCM 采样值序列。单个 block 的大小在 wav 头的 nBlockAlign 字段中表示。其中单声道和双声道的 preamble 格式又有些区别:
单声道 preamble 格式
byte 0 block predictor (builtin predictors are in the range [0..6] but others can be manually defined)bytes 1-2 initial delta bytes 3-4 sample 1 bytes 5-6 sample 2
复制代码立体声 preamble 格式
byte 0 left channel block predictor (should be [0..6])byte 1 right channel block predictor (should be [0..6]) bytes 2-3 left channel initial idelta bytes 4-5 right channel initial idelta bytes 6-7 left channel sample 1 bytes 8-9 right channel sample 1 bytes 10-11 left channel sample 2 bytes 12-13 right channel sample 2
复制代码preamble 中主要包含了实现自适应差分机制相关的参数,除此除外在末尾还存储了两个原始采样值,这不难理解:由于差分过程是通过比较与前一值的差异得到当前值,因此需要两个初始采样(反映此 block 波形变化剧烈程度)作为基础,从而计算相关自适应参数,并解码半字节序列递推解出整一个 block 的 PCM 数据,依次处理所有 block 完成整个音频的解码。
数据解码原始 PCM 为 16bit 位深,故 preamble 用了 2Byte 表示初始采样,而 ADPCM 压缩后只需 4bit(即 nibble 半字节) 表示一个采样,所以半字节序列中的 1Byte 能保存两个采样。
借助 preamble 中的参数变量外加三个表格,再经过一系列的运算便能解码 ADPCM 数据,得到完整 16bit PCM 格式音频,计算过程如下:
* predictor = ((sample1 * coeff1) + (sample2 * coeff2)) / 256* predictor += (signed)nibble * delta (note that nibble is 2's complement) * clamp predictor within signed 16-bit range * PCM sample = predictor * send PCM sample to the output * shuffle samples: sample 2 = sample 1, sample 1 = calculated PCM sample * compute next adaptive scale factor: delta = (AdaptationTable[nibble] * delta) / 256 * saturate delta to lower bound of 16
复制代码AdaptationTable、AdaptCoeff1 和 AdaptCoeff2三个表格存储了计算中用到的一些因子系数,页面中也给出了数组定义:
int AdaptationTable [] = { 230, 230, 230, 230, 307, 409, 512, 614, 768, 614, 512, 409, 307, 230, 230, 230 } ; // These are the 'built in' set of 7 predictor value pairs; additional values can be added to this table by including them as metadata chunks in the WAVE header int AdaptCoeff1 [] = { 256, 512, 0, 192, 240, 460, 392 } ; int AdaptCoeff2 [] = { 0, -256, 0, 64, 0, -208, -232 } ;
复制代码在网上能找到许多 ADPCM 的示例代码,但有许多人评论不能用、有杂音,这往往是编码标准没对上,或者使用姿势不正确,甚至代码本身就有问题。与其用零散的不规范例程,还不如直接去经典大项目里「抠代码」,规范性统一性和用法都有参考,FFmpeg 项目则是音视频编解码领域的「代码库」。
FFmpeg ADPCM 核心解码模块:FFmpeg: libavcodec/adpcm.c Source File
在文件末尾的宏函数列表中包含了 FFmpeg 所实现的所有 ADPCM 标准,其中的 AV_CODEC_ID_ADPCM_MS 是本文要实现的 MS 格式。
...ADPCM_DECODER(AV_CODEC_ID_ADPCM_IMA_RAD, sample_fmts_s16, adpcm_ima_rad, "ADPCM IMA Radical"); ADPCM_DECODER(AV_CODEC_ID_ADPCM_IMA_SMJPEG, sample_fmts_s16, adpcm_ima_smjpeg, "ADPCM IMA Loki SDL MJPEG"); ADPCM_DECODER(AV_CODEC_ID_ADPCM_IMA_WAV, sample_fmts_s16p, adpcm_ima_wav, "ADPCM IMA WAV"); ADPCM_DECODER(AV_CODEC_ID_ADPCM_IMA_WS, sample_fmts_both, adpcm_ima_ws, "ADPCM IMA Westwood"); ADPCM_DECODER(AV_CODEC_ID_ADPCM_MS, sample_fmts_s16, adpcm_ms, "ADPCM Microsoft"); ADPCM_DECODER(AV_CODEC_ID_ADPCM_MTAF, sample_fmts_s16p, adpcm_mtaf, "ADPCM MTAF"); ADPCM_DECODER(AV_CODEC_ID_ADPCM_PSX, sample_fmts_s16p, adpcm_psx, "ADPCM Playstation"); ...
复制代码adpcm.c 文件包含众多标准的处理,总代码量一千多行,便于分析起见,剔除没用到的代码,保留 MS ADPCM 相关部分,简化后的文件只有两百多行,核心函数是 adpcm_ms_expand_nibble() 和 adpcm_decode_frame():
static inline int16_t adpcm_ms_expand_nibble(ADPCMChannelStatus *c, int nibble){ int predictor; predictor = (((c->sample1) * (c->coeff1)) + ((c->sample2) * (c->coeff2))) / 64; predictor += ((nibble & 0x08)?(nibble - 0x10):(nibble)) * c->idelta; c->sample2 = c->sample1; c->sample1 = av_clip_int16(predictor); c->idelta = (ff_adpcm_AdaptationTable[(int)nibble] * c->idelta) >> 8; if (c->idelta < 16) c->idelta = 16; if (c->idelta > INT_MAX/768) { av_log(NULL, AV_LOG_WARNING, "idelta overflow\n"); c->idelta = INT_MAX/768; } return c->sample1; }
复制代码adpcm_ms_expand_nibble() 函数按照 MultimediaWiki 中描述的解码流程,对 predictor、coeff和 idelta 进行运算,将 4bit 的 ADPCM 数据 nibble 展开得到 16bit 原始 sample。
函数 adpcm_decode_frame() 则完成对 block 的处理,包括解析出 preamble 和 nibbles 序列数据、计算解码参数初始值、循环调用 adpcm_ms_expand_nibble() 完成解码,代码如下:
static int adpcm_decode_frame(AVCodecContext *avctx, void *data, int *got_frame_ptr, AVPacket *avpkt) { AVFrame *frame = data; const uint8_t *buf = avpkt->data; int buf_size = avpkt->size; ADPCMDecodeContext *c = avctx->priv_data; ADPCMChannelStatus *cs; int n, m, channel, i; int16_t *samples; int16_t **samples_p; int st; /* stereo */ int count1, count2; int nb_samples, coded_samples, approx_nb_samples, ret; GetByteContext gb; bytestream2_init(&gb, buf, buf_size); nb_samples = get_nb_samples(avctx, &gb, buf_size, &coded_samples, &approx_nb_samples); if (nb_samples <= 0) { av_log(avctx, AV_LOG_ERROR, "invalid number of samples in packet\n"); return AVERROR_INVALIDDATA; } /* get output buffer */ frame->nb_samples = nb_samples; if ((ret = ff_get_buffer(avctx, frame, 0)) < 0) return ret; samples = (int16_t *)frame->data[0]; samples_p = (int16_t **)frame->extended_data; /* use coded_samples when applicable */ /* it is always <= nb_samples, so the output buffer will be large enough */ if (coded_samples) { if (!approx_nb_samples && coded_samples != nb_samples) av_log(avctx, AV_LOG_WARNING, "mismatch in coded sample count\n"); frame->nb_samples = nb_samples = coded_samples; } st = avctx->channels == 2 ? 1 : 0; int block_predictor; block_predictor = bytestream2_get_byteu(&gb); if (block_predictor > 6) { av_log(avctx, AV_LOG_ERROR, "ERROR: block_predictor[0] = %d\n", block_predictor); return AVERROR_INVALIDDATA; } c->status[0].coeff1 = ff_adpcm_AdaptCoeff1[block_predictor]; c->status[0].coeff2 = ff_adpcm_AdaptCoeff2[block_predictor]; if (st) { block_predictor = bytestream2_get_byteu(&gb); if (block_predictor > 6) { av_log(avctx, AV_LOG_ERROR, "ERROR: block_predictor[1] = %d\n", block_predictor); return AVERROR_INVALIDDATA; } c->status[1].coeff1 = ff_adpcm_AdaptCoeff1[block_predictor]; c->status[1].coeff2 = ff_adpcm_AdaptCoeff2[block_predictor]; } c->status[0].idelta = sign_extend(bytestream2_get_le16u(&gb), 16); if (st){ c->status[1].idelta = sign_extend(bytestream2_get_le16u(&gb), 16); } c->status[0].sample1 = sign_extend(bytestream2_get_le16u(&gb), 16); if (st) c->status[1].sample1 = sign_extend(bytestream2_get_le16u(&gb), 16); c->status[0].sample2 = sign_extend(bytestream2_get_le16u(&gb), 16); if (st) c->status[1].sample2 = sign_extend(bytestream2_get_le16u(&gb), 16); *samples++ = c->status[0].sample2; if (st) *samples++ = c->status[1].sample2; *samples++ = c->status[0].sample1; if (st) *samples++ = c->status[1].sample1; for(n = (nb_samples - 2) >> (1 - st); n > 0; n--) { int byte = bytestream2_get_byteu(&gb); *samples++ = adpcm_ms_expand_nibble(&c->status[0 ], byte >> 4 ); *samples++ = adpcm_ms_expand_nibble(&c->status[st], byte & 0x0F); } if (avpkt->size && bytestream2_tell(&gb) == 0) { av_log(avctx, AV_LOG_ERROR, "Nothing consumed\n"); return AVERROR_INVALIDDATA; } *got_frame_ptr = 1; if (avpkt->size < bytestream2_tell(&gb)) { av_log(avctx, AV_LOG_ERROR, "Overread of %d < %d\n", avpkt->size, bytestream2_tell(&gb)); return avpkt->size; } return bytestream2_tell(&gb); }
复制代码把 adpcm_ms_expand_nibble() 和 adpcm_decode_frame() 两个函数的核心功能理解后,抽出主要代码,照葫芦画瓢实现我们自己的 ADPCM 解码器,这是我改的一个版本 lib_adpcm.c,实现了单个 block 解码接口 adpcm_decode_block(),同时简化了一些 FFmpeg 的代码写法,能达到同样的效果:
#include <stdint.h> #include <string.h> #include <limits.h> #include "lib_adpcm.h" /* These are for MS-ADPCM */ /* ff_adpcm_AdaptationTable[], ff_adpcm_AdaptCoeff1[], and ff_adpcm_AdaptCoeff2[] are from libsndfile */ const int16_t adpcm_AdaptationTable[] = { 230, 230, 230, 230, 307, 409, 512, 614, 768, 614, 512, 409, 307, 230, 230, 230 }; /** Divided by 4 to fit in 8-bit integers */ const uint8_t adpcm_AdaptCoeff1[] = { 64, 128, 0, 48, 60, 115, 98 }; /** Divided by 4 to fit in 8-bit integers */ const int8_t adpcm_AdaptCoeff2[] = { 0, -64, 0, 16, 0, -52, -58 }; static const int av_clip_int16(int a) { if (a > 32767) { a = 32767; } else if (a < -32768) { a = -32768; } return a; } static int16_t adpcm_ms_expand_nibble(adpcm_block_info *block_info, int nibble) { int predictor; predictor = (((block_info->sample1) * (block_info->coeff1)) + ((block_info->sample2) * (block_info->coeff2))) / 64; predictor += ((nibble & 0x08)?(nibble - 0x10):(nibble)) * block_info->delta; block_info->sample2 = block_info->sample1; block_info->sample1 = av_clip_int16(predictor); block_info->delta = (adpcm_AdaptationTable[(int)nibble] * block_info->delta) >> 8; if (block_info->delta < 16) block_info->delta = 16; if (block_info->delta > INT_MAX/768) { printf("[adpcm]%s:%d idelta overflow\n", __FUNCTION__, __LINE__); block_info->delta = INT_MAX/768; } return block_info->sample1; } int adpcm_decode_block(int16_t *output, uint8_t *input, adpcm_block_info *block_info) { uint8_t *read_ptr = RT_NULL; uint32_t nb_samples = 0; int n; block_info->block_predictor = *input; block_info->delta = (int16_t)input[2] << 8 | input[1] ; block_info->sample1 = (int16_t)input[4] << 8 | input[3]; block_info->sample2 = (int16_t)input[6] << 8 | input[5]; block_info->nibbles_prt = &input[7]; read_ptr = block_info->nibbles_prt; nb_samples = (ADPCM_BLOCK_SIZE-6)*2; if (block_info->block_predictor > 6) { printf("[adpcm]%s:%d ERROR: block_info->block_predictor = %d\n", __FUNCTION__, __LINE__, block_info->block_predictor); return -1; } block_info->coeff1 = adpcm_AdaptCoeff1[block_info->block_predictor]; block_info->coeff2 = adpcm_AdaptCoeff2[block_info->block_predictor]; *output++ = block_info->sample2; *output++ = block_info->sample1; for(n = (nb_samples - 2) / 2; n > 0; n--) { int byte = *read_ptr; *output++ = adpcm_ms_expand_nibble(block_info, byte >> 4 ); *output++ = adpcm_ms_expand_nibble(block_info, byte & 0x0F); read_ptr++; } return nb_samples*sizeof(int16_t); }
复制代码在使用上也很方便,ADPCM 也是通过 WAV 容器封装,这部分的解析代码可以复用,只要定位到音频数据位置,接着不停从文件中读取、每次处理 block_size 字节,循环至文件结束即可,测试代码如下:
#define ADPCM_BLOCK_SIZE 1024 #define PLAY_ADPCM_READ_SIZE ADPCM_BLOCK_SIZE #define PLAY_BUFFER_SIZE PLAY_ADPCM_READ_SIZE*4 int main() { ... // 打开文件、解析 WAV 容器 while (1) { memset(read_buffer, 0, PLAY_ADPCM_READ_SIZE); memset(write_buffer, 0, PLAY_BUFFER_SIZE); read_size = fread(read_buffer, 1, PLAY_ADPCM_READ_SIZE, fp); if (read_size == 0) break; decode_byte = adpcm_decode_block((int16_t*)write_buffer, (uint8_t*)read_buffer, &b_info); sound_device_write(dev, 0, write_buffer, decode_byte); // 解码后的 PCM 数据写入声卡设备播放 } // 关闭文件、释放资源 ... }
复制代码[size=0.95em]参考资料来自:国际哥的独立博客(链接:http://www.shaoguoji.cn/2019/08/04/hardcore-audio-2/)
- Microsoft ADPCM - MultimediaWiki
- FFmpeg: libavcodec/adpcm.c Source File
- ADPCM Overview - Windows applications | Microsoft Docs
- ADPCM压缩算法 - he91-com - ITeye博客
- ADPCM编码和解码 - creepz - 博客园



 /3
/3 
