
法国设计师菲利普 斯塔克和杰罗姆 奥利韦(Jerome Olivet)用全息与语音控制技术设计一款手机,它就是Alo。这款智能手机与现在的手机安全不同。

如图,手机的外壳半透明,细长,像凝胶一样,拿在手上很舒适。手机没有触摸屏,它用3D全息图像投放电影与信息。
未来,语音技术将会统治世界,或许Alo正是为这个世界准备的。
奥利韦喜欢用新技术设计产品,他说:“Alo的所有手机功能都使用语音界面,阅读SMS和邮件也用语音,我们可以用声音输入信息,而不是文本。手机的摄像头像‘眼睛’一样,它可以阅读文本,识别人脸。手机还可以用3D全息图像投射电影或者信息。”
手机完全由语音控制,中央部分是铝合金制造的。柔韧的外壳相当于触觉界面,可以感知温度、振动信息。
奥利韦说:“半透明皮肤会根据活动发热,振动、通信。如果受到损害,皮肤会自动修复。”

自从亚马逊Echo和谷歌Home推出之后,语音助手进入许多家庭。当语音识别高度成熟,不再需要其它控制方式,我们就可以使用Alo手机了。目前Alo仍然只是一个概念,不过奥利韦准备开发原型机,他与法国电子企业Thomson合作开发。
奥利韦说:“手机完全使用AI,我们与设备不再是分离的。”
今年晚些时候,两名设计师就会开发原型设备。小米Mi Mix就是斯塔克设计的,这款手机获得了好评,手机几乎没有边框,屏幕占了手表前表面的91%。
下面来简单科普一下全息与语音控制技术的基本知识。
全息投影技术
全息投影技术(front-projected holographic display)也称虚拟成像技术是利用干涉和衍射原理记录并再现物体真实的三维图像的技术。全息投影技术不仅可以产生立体的空中幻象,还可以使幻象与表演者产生互动,一起完成表演,产生令人震撼的演出效果。
全息投影技术原理
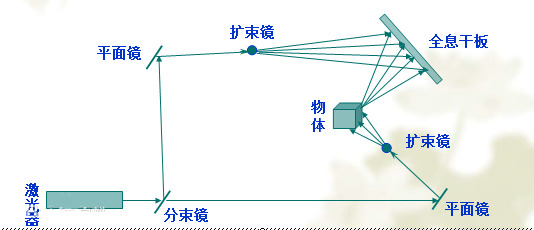
其第一步是利用干涉原理记录物体光波信息,此即拍摄过程:被摄物体在激光辐照下形成漫射式的物光束;另一部分激光作为参考光束射到全息底片上,和物光束叠加产生干涉,把物体光波上各点的位相和振幅转换成在空间上变化的强度,从而利用干涉条纹间的反差和间隔将物体光波的全部信息记录下来。记录着干涉条纹的底片经过显影、定影等处理程序后,便成为一张全息图,或称全息照片。
其第二步是利用衍射原理再现物体光波信息,这是成象过程:全息图犹如一个复杂的光栅,在相干激光照射下,一张线性记录的正弦型全息图的衍射光波一般可给出两个象,即原始象(又称初始象)和共轭象。再现的图像立体感强,具有真实的视觉效应。全息图的每一部分都记录了物体上各点的光信息,故原则上它的每一部分都能再现原物的整个图像,通过多次曝光还可以在同一张底片上记录多个不同的图像,而且能互不干扰地分别显示出来。

上图是一张全息投影的地形图。
语音识别技术
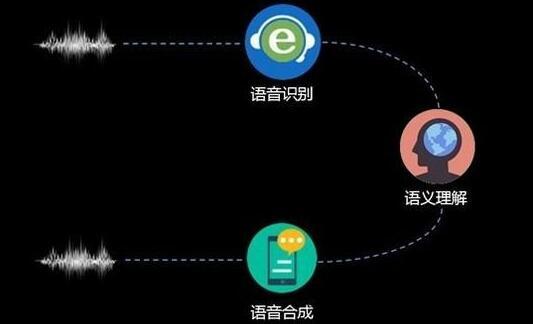
语音识别技术,也被称为自动语音识别Automatic Speech Recognition,(ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。与说话人识别及说话人确认不同,后者尝试识别或确认发出语音的说话人而非其中所包含的词汇内容。
语音识别技术的应用包括语音拨号、语音导航、室内设备控制、语音文档检索、简单的听写数据录入等。语音识别技术与其他自然语言处理技术如机器翻译及语音合成技术相结合,可以构建出更加复杂的应用,例如语音到语音的翻译。
语音识别技术所涉及的领域包括:信号处理、模式识别、概率论和信息论、发声机理和听觉机理、人工智能等等。
语音识别系统提示客户在新的场合使用新的口令密码,这样使用者不需要记住固定的口令,系统也不会被录音欺骗。文本相关的声音识别方法可以分为动态时间伸缩或隐马尔可夫模型方法。文本无关声音识别已经被研究很长时间了,不一致环境造成的性能下降是应用中的一个很大的障碍。
语音识别工作原理
动态时间伸缩方法使用瞬间的、变动倒频。1963年Bogert et al出版了《回声的时序倒频分析》。通过交换字母顺序,他们用一个含义广泛的词汇定义了一个新的信号处理技术,倒频谱的计算通常使用快速傅立叶变换。
从1975年起,隐马尔可夫模型变得很流行。运用隐马尔可夫模型的方法,频谱特征的统计变差得以测量。文本无关语音识别方法的例子有平均频谱法、矢量量化法和多变量自回归法。
平均频谱法使用有利的倒频距离,语音频谱中的音位影响被平均频谱去除。使用矢量量化法,语者的一套短期训练的特征向量可以直接用来描绘语者的本质特征。但是,当训练向量的数量很大时,这种直接的描绘是不切实际的,因为存储和计算的量变得离奇的大。所以尝试用矢量量化法去寻找有效的方法来压缩训练数据。Montacie et al在倒频向量的时序中应用多变量自回归模式来确定语者特征,取得了很好的效果。
想骗过语音识别系统要有高质量的录音机,那不是很容易买到的。一般的录音机不能记录声音的完整频谱,录音系统的质量损失也必须是非常低的。对于大多数的语音识别系统,模仿的声音都不会成功。用语音识别来辨认身份是非常复杂的,所以语音识别系统会结合个人身份号码识别或芯片卡。
语音识别系统得益于廉价的硬件设备,大多数的计算机都有声卡和麦克风,也很容易使用。但语音识别还是有一些缺点的。语音随时间而变化,所以必须使用生物识别模板。语音也会由于伤风、嗓音沙哑、情绪压力或是青春期而变化。语音识别系统比指纹识别系统有着较高的误识率,因为人们的声音不像指纹那样独特和唯一。对快速傅立叶变换计算来说,系统需要协同处理器和比指纹系统更多的效能。目前语音识别系统不适合移动应用或以电池为电源的系统。
语音识别系统结构
一个完整的基于统计的语音识别系统可大致分为三部分:
(1)语音信号预处理与特征提取;
(2)声学模型与模式匹配;
(3)语言模型与语言处理;
语音信号预处理与特征提取。
语音识别基本方法
一般来说,语音识别的方法有三种:基于声道模型和语音知识的方法、模板匹配的方法以及利用人工神经网络的方法。
文章来源:综合(腾讯数码Databoy)、百度百科等整理


 /4
/4 

