
上面三个词都是AlphaGo获胜的缘由。但对很多只是看过几次报道的人来说,对这三个概念之间的关系,经常傻傻分不清楚!
人工智能、机器学习、深度学习之间,到底有什么联系和区别?
这里,主页君准备了3000字为你解答。但如果你只想花两分钟搞懂,只看下面三段就OK了。
简单来说,人工智能、机器学习、深度学习之间关系就是这样的:

人工智能从萧条到繁荣:人工智能的60年发展历程
由机器诠释的人类智能:小到手机上使用的图像识别软件,大到《钢铁侠》中的贾维斯,你都可以将其归在人工智能的范畴里。人工智能既可以是科幻,也可以是我们生活中的一部分;
机器学习
实现人工智能的一种方式:这种方法的特别之处在于,它不是通过手动编写特定的程序来完成某项工作,而是借助海量数据进行「训练」,让机器自己学会如何完成任务,就像人通过积累经验来掌握一项新本领一样;
深度学习
一种实现机器学习的方法:机器学习中有一种算法叫做「人工神经网络」,是指通过模拟大脑神经网络处理、记忆信息的方式进行信息处理。深度学习是在人工神经网络基础上发展而来,通过建立大得多也复杂得多的神经网络,来获得更精准的效果。但这种方法需要消耗巨大的计算资源。深度学习现在这么火,和当今计算性能的飞跃有着密切联系。
1956年,以约翰·麦卡锡为首的一些科学家在达特矛斯会议上首次提出了人工智能这一概念。在那之后,人工智能就进入了我们的想象,并在实验研究当中不断酝酿。
几十年来,人工智能时而被誉为是未来人类文明的关键,时而被当做是一个头脑发烧的概念被扔到技术的垃圾堆中。坦白地说,在2012年之前,人工智能就是这样在这两者之间交杂。
过去几年,尤其是从2015年开始,人工智能迎来了大爆发。这很大程度上与GPU的广泛应用密切相关,GPU让并行处理速度更快、成本更低、更强大。这也和几乎无限的存储能力以及各类数据洪流息息相关,包括图像、文本、交易、测绘数据等任何你想得到的数据类型。
从最早的萧条时代,到今天催生出大量每天有数亿人使用的人工智能应用的繁荣景象,这期间经历了怎样的演变,继续往下看。
人工智能:由机器诠释的人类智能

King me:一款西洋跳棋程序,作为人工智能的早期案例,曾在上世纪50年代引发一阵轰动
回到1956年那场会议上,当时人工智能先驱们的梦想,是构建具有人类智力特征的高级机器,这就是所谓的「广义人工智能」。它拥有和我们人类相同或更多的感知能力、所有的理智,以及和人类一样的思考事物的能力。
这些概念在很多老电影中均有体现,它可能是人类的朋友,比如《星球大战》里的C-3PO,也有可能是敌人,比如电影《终结者》里的杀人机器。这种「广义人工智能」有充足的理由出现在各类科幻作品当中,因为我们目前还没有实现。
我们能够实现的人工智能,可以认为是「狭义人工智能」,它指的是能够完成某项特定工作、甚至完成得比人类还要好的技术,比如Pinterest上的图像分类,Facebook的人脸识别等等。
这些都是「狭义人工智能」的典型例子。这些技术诠释了人类某些方面的智慧,但是,他们的智慧从何而来?这就是下面要讲的——机器学习。
机器学习:实现人工智能的一种方式

Spam free diet:机器学习为你清理收件箱中(大部分)的垃圾邮件
机器学习最基本的做法是通过算法来分析数据,从中学习,然后做出判断或预测。所以,这种方法并不是指手动编写带有特定指令、用来完成某些特定任务的软件,而是通过海量数据和算法来「训练」,让机器自己学会如何完成任务。
机器学习源自那些人工智能先驱们的思想以及演化了多年的算法,包括决策树学习、归纳逻辑编程、聚类、增强学习和贝叶斯网络。但正如我们所知,这些早期的机器学习方法都没能实现广义人工智能的最终目标,甚至连狭义人工智能的一小部分目标也没能实现。
多年的实践证明,计算机视觉是机器学习的最佳应用领域之一,尽管它依然需要大量手动编写各种分类器的编程工作。

以大家非常熟悉的「STOP停车标志牌」为例,人们需要编写边缘检测程序,以识别出物体的轮廓;编写形状检测程序,以识别出它是否有8个边;编写能够检测字母「S-T-O-P」的分类器……利用这些手动编写的分类器,可以开发出理解图像的算法并「学会」判定它是否是一个停车标志。
这种方式看起来不错,但还不够好。因为如果遇上雾天,或者是被道路上的树稍微遮挡时,标志牌便会很难看清。这就是直到不久前,计算机视觉和图像检测还比不上人类的其中一个原因——他们太容易出错了。
是时间和正确的学习算法,改变了这一切!
深度学习:一种实现机器学习的方法

Herding cats:从 YouTube 视频中挑出猫咪图片,是深度学习的首次突破性表现之一
模拟人脑的信息处理方式
人工神经网络,这是源自最早进行机器学习的那群人中的另外一种算法,其概念已有几十年历史了。神经网络的灵感来自我们对生物大脑的理解——所有神经元之间相互连接。但是,生物大脑中,神经元可以在特定物理距离内连接到任何其他神经元,而人工神经网络中的层、连接和数据传播方向都是离散的。
比如,你可以把一个图像切成一堆碎片,然后输入到神经网络的第一层中。然后第一层中的那些单个神经元将数据传输给第二层,第二层再传给第三层……一直传输到最后一层并输出最终结果。
在这一过程中,每个神经元会有一个输入权重,或者叫加权值,用来评估其所执行的任务是否准确。最终的输出由所有这些加权值来确定。
难题:需要大量计算资源
依然以停车标志为例。现在,我们可以把该图像的元素「切碎」,然后由神经元来对它的形状、颜色、字母、尺寸等等进行一一「检查」。神经网络的最终任务是推断出它是不是一个停车标志。这里涉及一个「概率向量」的概念,是一种基于权重的推断。在这个例子中,系统最终可能有86%的把握认为它是一个停车标志,7%的把握认为它是一个限速标志,5%的把握认为是挂在树上的风筝等等。
当网络正在进行调整或「训练」时会产生大量的错误答案,这对神经网络来说是一个非常好的机会,因为它所需要的就是训练。它需要通过数十万、甚至数百万个图像的训练,直到神经元的加权值得到精准调整,最终做到每一次都能产生正确的答案——无论有没有雾、有没有雨,都能看出那是一个停车标志牌。换句话说,神经网络最终领悟到了停车标志应该看起来是什么样的。
这个例子看上去很好理解,但事实上,直到最近几年,神经网络都是被人工智能研究圈子避开的领域。原因很简单,即便是最基本的神经网络,都需要巨大的计算资源支持。的确有很多科学家自人工智能刚刚兴起之后就在做这方面的研究,但是「智能」的效果甚微,一直没有什么实际意义。
2012年的转折点
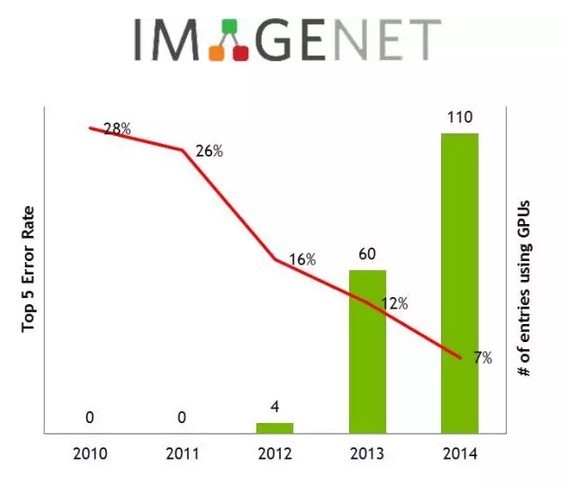
2012年的ImageNet视觉识别挑战赛改变了人们的看法。当时,多伦多大学首次利用GPU训练神经网络模型,一举将错误率从上一年的26%降低到16%(再上一年是28%),并夺得冠军。这被认为是深度学习爆发的标志性事件,在后来的ImageNet中,GPU的使用也呈现爆发增长。
吴恩达在2012年通过1000万个取自YouTube视频的图像所做的能够识别猫的系统,也同样让人意识到了深度学习的强大。吴恩达的突破实际上是在于将神经网络的规模进一步扩大,大幅增加层数和神经元的数量,然后投入海量数据来训练它——这正是深度学习所追求的。
如今,在一些应用场景中,通过深度学习训练机器来识别图像,做得比人类更好,不仅仅是识别猫咪,还包括确定血液中的癌症指标、磁共振成像扫描中的肿瘤指标等。谷歌的AlphaGo被训练用于围棋比赛,它通过反复与自己对抗来调整自己的神经网络。
感谢深度学习:让人工智能有了一个光明的未来
深度学习使得许多机器学习应用成为现实,也使得人工智能领域得到全面推广。深度学习执行任务的方式,让很多机器辅助功能成为可能,像是无人驾驶汽车、更好的预防保健、更好的电影推荐等等。
人工智能既是当下也是未来。在深度学习的帮助下,人工智能有朝一日将会达到我们一直以来所想象的在科幻作品当中的形态。
来源:英伟达中国



 /3
/3 
