
首先,结构流程如下图,viso用得少,图就画了个大概,也没仔细修饰润色,大家将就着看吧:
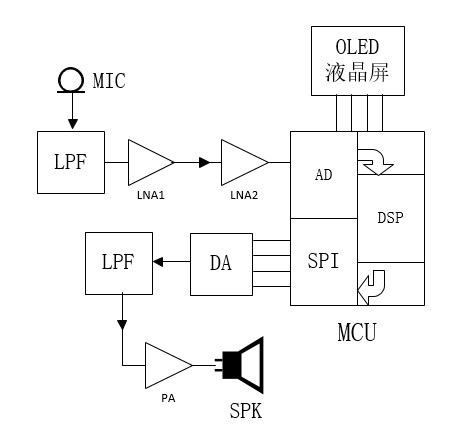
整个过程是这样的,驻极体话筒拾音后经过一个RC抗混叠低通预滤波,然后是两级三极管级联放大,因为后面的AD输入动态范围是0~3.3V,所以把信号幅度放大到大概±1.5V之间后通过电容耦合到AD输入端,AD采样以后变为数字信号,然后进行相应的DSP处理,处理完再通过SPI总线输出到外置DA芯片,然后经过一个二阶RC无源低通滤波器进入功放,通过一个OTL形式的三极管乙类互补推挽功放扩流后,推动两个并联的4欧喇叭。
了解了大概流程以后接下来就具体介绍各个部分吧,首先要说一点,因为想方便供电,所以平时我自己做东西玩都有一个特点,就是电源基本都是使用生活中最常见的usb5v供电,可以用手机充电器、电脑usb、充电宝等等,真的非常方便,之前同样参加了这个活动的旋转LED也是用跟大部分手机充电接口一样的microusb接口来供电的,这次也一样可以用microusb,还多加了一个一般5v直流电源用的圆形插孔。先来一张整机实物图:
 整机正面.jpg1600x900 235 KB
整机正面.jpg1600x900 235 KB 这次用到的放大器全都是用三极管分立元件来搭的,在这种要求几乎没有的地方用运放太简单了没意思,毕竟做着玩嘛,就是要搞事情,而且以前也很少直接用三极管做过放大器,顺便熟悉一下晶体管的使用;使用三极管而不用运放的另外一个重要原因,是之前说过的电源,这里用的5v单电源供电,太低了,这个电压下运放基本都用不成了,lm358或324貌似可以,但人家平时正常情况下也都是20多v电压下工作的,用在5v下也太憋屈了,即使能用,其输出动态范围也要比5v小不少,而AD输入需要3v左右的峰峰值,实际上我也试过,效果不好。其他的办法也不是没有,要不换好运放,要不就做个电源升压,但都是要花银子的,光这块折腾下来人民币怎么也得花个两位数。用三极管就不一样了,5v电源下保证3v的动态范围是完全没有问题的,而且几毛钱就能搞定,还是那句话:能省就省!
不经意间废话了不少,下面正式开始,首先是前置放大模块:
经过多次试验对比之后,话筒选用了一个坏掉的手机耳机线上拆下来的驻极体话筒。在multisim里面找了一圈没找着话筒或其类似物,所以输入端用了一个电阻来代替,输出端也一样,电容耦合输出以后加直流偏置到AD输入动态范围中点即3.3/2(v),用了一个大电阻来等效AD输入阻抗。看图说话:
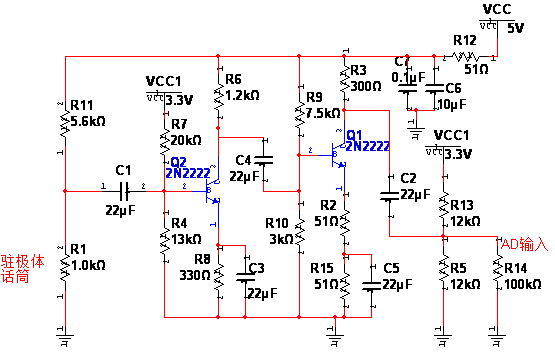
实际电路中两个三极管用的是高hfe低噪声的适合做单管放大的9014,经测量hfe是210左右且随温度漂移比较明显,multisim没有9014所以随便用了个npn来表示。图中各电阻电容值都是我实际电路中的真实值,制作过程除了一个万用表,没有其他仪器了,所以全靠计算加耳朵听效果来感觉以进行调整,真的做三极管电路没经验,不知道取值是否合适,也是想请大侠们给点建议。我先说一下我的思路,两级A类放大器级联,第一级输入端电阻都比较大,主要是考虑到话筒本身输出电阻较大,想从话筒获取尽可能大的电压信号,第二级电阻较小是想压低输出阻抗。电压增益的话理论估算第二级大概15dB,第一级能有20dB以上,加起来差不多40dB左右。
过程中遇到不少问题,最头疼的就是自激振荡了,开始时真是不懂为什么,课本上那些什么前后隔离度不够、反馈太深什么的道理好像都对应不进去,经过好一番折腾才弄明白那摩托车一般突突突的声音是前端放大器和功放使用了同一个直流电源且去耦不充分导致的,由于电源内阻的存在,功放使电源电压变化反馈到前置输入端形成了正反馈导致了自激,这真的是长了大大大见识了。但是我还是只有一个直流电源啊,所以折中如图所示,前置放大模块电源用了一个51欧电阻隔离,然后加了电容去耦,第一级的偏置使用LDO芯片AMS1117稳定输出的3.3v分压得到,这个3.3v顺便也作为AD输入端的偏置分压源,用稳定电压作为分压源一方面能防止自激,一方面也能降低噪声,因为据很有道理的说法说大部分噪声都是从基极偏压引入的,实际改变之后确实有很大改善。说到噪声,不得不说一下开始时没考虑到的一点,当时布线把AD输入信号线和SPI输出的数据线平行走了5cm左右,那就不得了了,导致噪声大得要命,也是经过一番排查才找出原因,真没想到以前以为很高大上的EMC问题就这么赤裸裸地摆在自己面前,其实想想也正常,那条spi数据线中以20Mbps的速度传输着数字信号到DA,这么近相邻平行走线怎么也难免耦合过来一些噪声,后来改了线路果然好多了。到这里,前置放大部分也是本机模拟电路中最考验技术的部分就说完了,这部分连回顾课本、设计计算、不断制作调试然后改善问题前后总共也花了两周左右的业余时间了。实际电路如下,电阻电容用的是0805的,所以可能看不太清,而且因为反复改了好多次,板子已经焊得不成样子了:
 背面电路.jpg1600x900 360 KB
背面电路.jpg1600x900 360 KB 接下来继续说另一块模拟部分吧,模拟说完了再说数字部分,另一部分就是功放了,这里用的是单电源的OTL形式的B类互补推挽功放,实际电路中npn用的是8050,pnp是8550,图:
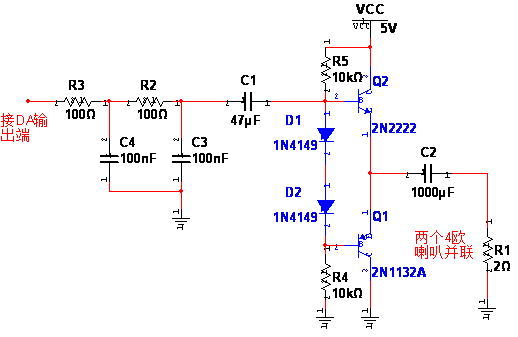
首先DA输出以后接二阶RC滤波滤除高频,由于后面功放输入阻抗不小,前面DA输出阻抗也不大,此处滤波要求也不是多严格,所以用个二阶无源RC随便滤一下就差不多了。此处R取100欧,C取100nF,理论计算截至频率16kHz左右,差不多了,实际实验过声音到15kHz时已经几乎听不见了。两管基极之间理应用两个硅管消除交越失真,实际调试以后觉得用三个1n4148效果似乎更好一些,大概是让两个三极管处于微导通了吧,增加了一点直流功耗但减小了失真。由于负载是两个4欧喇叭并联的,负载很重了,所以功放输出耦合电容一定要够大才行,这里用的是一个1000uF的电解电容。正面电路板如下,请忽略DA芯片下方红线旁的四个三极管,那是试验用的:
 正面平视_已标注.jpg1600x900 843 KB
正面平视_已标注.jpg1600x900 843 KB 好了,纯模拟部分就说完了,下面说一下数模转换,这里DA用的是TI的TLV5618双列直插式封装的芯片,12bit,双通道,spi串行接口,spi时钟速率最高20MHz,算下来最高数据更新速率是20MHz/16bit=1.25MHz,用于音频足矣,电源3点几到5点几伏都行。关于DA没什么更多好说的,芯片就是直接接上就能用。
这样的话所有的单片机之外的硬件部分就介绍完了,下面是单片机部分。单片机的工作包括了流程中的AD采样、DSP处理以及SPI输出。
大概说一下这个单片机跟这次应用有关的配置,单片机型号是TivaC系列的TM4C123GH6PMI,32位的arm-coretex-m4f内核处理器,最高主频80MHz,带有一个硬件浮点运算单元(FPU),两个12bitAD转换模块共用模拟16路输入通道,每个模块最高采样率1MHz,有4个同步串行接口模块,我们这里用的spi就是用的它的这种模块,还有一个32通道的可配置直接存储器读写(DMA)控制器,还有32KB的单周期SRAM和256KB的单周期FLASH。单片机板子是这个样子的:
 launchpad正面.jpg1600x900 243 KB
launchpad正面.jpg1600x900 243 KB 网上有人说实际使用下来这种m4内核的处理器性能已经相当于一些中低端的DSP专用处理器了,所以用于我这种应用中是绰绰有余的。尤其是它的FPU还有DMA这种功能用于音频采集计算是相当合适而且给力的,实际上我试过,开启FPU后进行浮点型运算比不开启FPU进行相同数值的定点运算还要快不少。我们这个系统要实现那些设想的功能靠的就是进行大量的时域卷积还有快速傅里叶变换(FFT),FPU在这里表现得真真是极好的。DMA的话可以让AD采到的数据不经cpu干预就直接存储到存储器中,SPI也可以无需消耗cpu资源就直接从存储器读取数据发送给DA,这样cpu就可以专心计算了,DMA与这种应用真的是天造地设的绝配啊。但是我这次并没有使用DMA,本来想的是先不用DMA做一套,然后使用DMA再做一套对比一下,结果第一套到现在还没做成,真是悲伤的故事。
AD默认1MHz采样率,这里采样使用8分之一采样率、4点overflow,理论采样率应该是1MHz/8/4=31.25kHz,但由于没用DMA而是使用中断读取数据再触发采样的方式,进中断、软件触发消耗了一些时钟周期,最后采样率是29.694kHz,跟我们之前说的低通滤波器截止频率16kHz左右不谋而合。SPI发送给DA的速率与AD采样速率相同。剩下的就是数字信号处理(DSP)部分了。软件流程图如下:
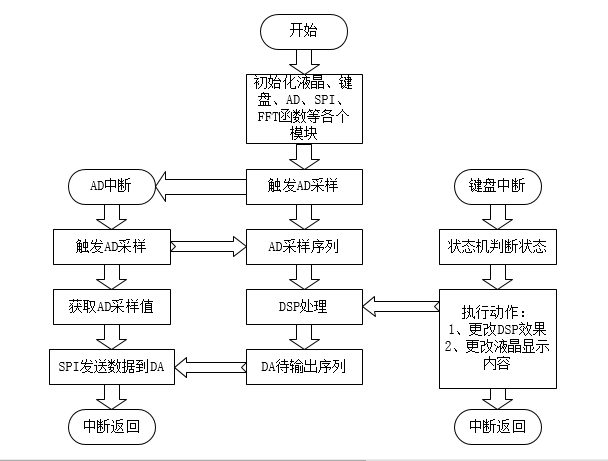
到现在,万事俱备,只欠DSP了,然而,DSP这块又是一片新天地,名堂多了去了,上学期数字信号处理期末考因为不好好学习而又几乎裸考而挂了大学唯一一门课,虽说基本没什么影响,但心里始终有点在意,这也是我这次做这个东西的主要原因之一了,就是不想在数字信号处理这方面完全是个小白。所以没办法,想做出效果只能硬着头皮去看书、上网,以前不好好学,现在不还以后也迟早是要还的,只不过可能还的方式不一样罢了。
其他看书什么的就不说了,这里先说一下这个DSP在单片机上的实现,这里面肯定是要用到FFT和IFFT变换的,这些变换函数在网上也有一些,但这里能用的都是通用的C语言程序,我试过那么一两个,由于是通用的,并没有针对某一个硬件平台进行过优化,所以实际用起来效果不行,主要是速度太慢,在就这个单片机来说,AD采样一帧数据用的时间不够cpu对一帧数据进行计算,无法保证实时性。
后来了解到ARM公司专门针对ARM内核的处理器有一个coretex微处理器软件接口标准(CMSIS),其中就有DSP库,里面的函数都是针对各个arm处理器深度定制、专门优化了的,能够最大限度地发挥处理器的性能来提高计算速度,比如适用于m4的函数就可以选择使用FPU单元大大提高计算速度。对于stm32的M4每个处理器,官方的stm32库里面已经集成了CMSIS,可以直接使用,但是对于这里所用的tiva系列却没有,ARM官网下载的CMSIS里面也分别提供了用于keil和IAR以及GCC等几大编译器的库,但是我用的开发环境(IDE)是TI的CCS,用的编译器是TI自己的编译器,所以办法如下:
1、换开发环境,用keil或IAR;
2、继续用ccs,但换用ccs自带的GCC编译器;
3、把CMSIS重新编译成适用于CCS里面TI编译器的库文件。
结果是,我都试了,每种办法都遇到了各种各样的问题,让当时完全理不清各种库、编译器以及各种复杂关系的我折腾了一周多,搜索过程中确实体会到了国内stm32比tiva普及、资料比tiva多的事实,找遍了TI官网E2E社区,觉得那几天看过的英文比我往年一整年里看过的都要多,到最后都要放弃了,不抱一点希望地在TI官网上瞎转悠,竟然在一个看起来毫不相关的地方找到了CMSIS移植到ccs的教程,简直要哭了,经过一下午折腾终于弄妥,事实证明之前搞了那么久搞不对是有道理的,因为照教程说的那样,在什么都不懂的我看来确实是挺复杂的。在取得了这样具有里程碑意义的进展后,那天心情愉快,一怒之下把宿舍里里外外全打扫了一遍嘻嘻嘻。。。重编译完成后的库在ccs里面是这样的,各个文件夹下的各种函数都可以直接调用了:
这样的话,终于可以安心写算法了,最后整理了一下实现这些功能的思路是这样的:
回声:每次采集的一个时间序列先经过延时一段时间,然后减小一些幅度后叠加在当时的序列上输出,便能实现回声的效果,相当于时域卷积一个形如(1,0,0,0,0.5,0.25,0.125)的序列,其中元素1表示0时刻的响应,0的个数表示延时长短,0.5表示之前时刻的输入的响应。就像在一个房间里说话有回声,1表示自己直接听到自己说出的声音,0的个数即延时长短由人到墙壁的距离决定,而这个0.5就相当于房间墙壁对声音的反射系数,后面的0.25和0.125表示多次反射的声音。实际程序实现中我并不是通过卷积运算来实现的,因为所用的卷积函数是通过FFT后频域相乘再IFFT得到的,对于点数不多的卷积这么做反而效率不高,而且该库函数中FFT和IFFT运算点数只能是2的整数次幂,不能自由调整,所以实际中我用了几个缓存数组,用字符串处理的方式来实现同样的卷积效果,看起来比较繁琐但效率应该会高一些。最后回声效果还是不错的。
下面是变调不变速,这次做的是一个采集音频实时处理并回放的系统,要保证声音音调改变而不改变说话速度,所以必须要在输入输出序列长度相等的条件下改变输出序列的频率。模拟输入的原始序列频谱和波形如下:
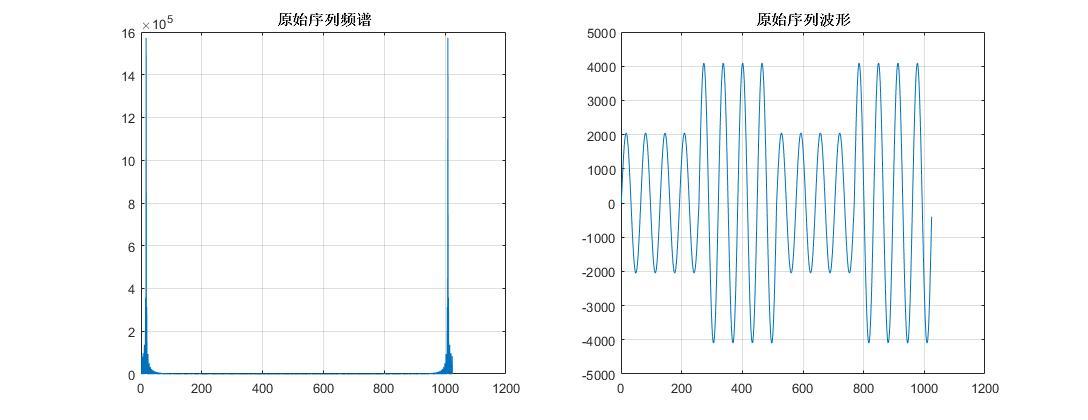 原始序列频谱 波形.jpg1088x420 40 KB
原始序列频谱 波形.jpg1088x420 40 KB 男声变女声:用的是简单的办法,虽然效果可能差一些,但是想先做出来再说,以后再考虑用其他复杂的算法。是这样的,对AD采进来的序列做FFT运算变换到频域,然后在频域上对频谱低端补零,这样频谱就被整体抬高了,然后做FFT反变换到时域,这样就得到了升调后的声音,然后进行时域抽样就能得到和原序列长度一样的序列了。matlab模拟结果表示是可行的:
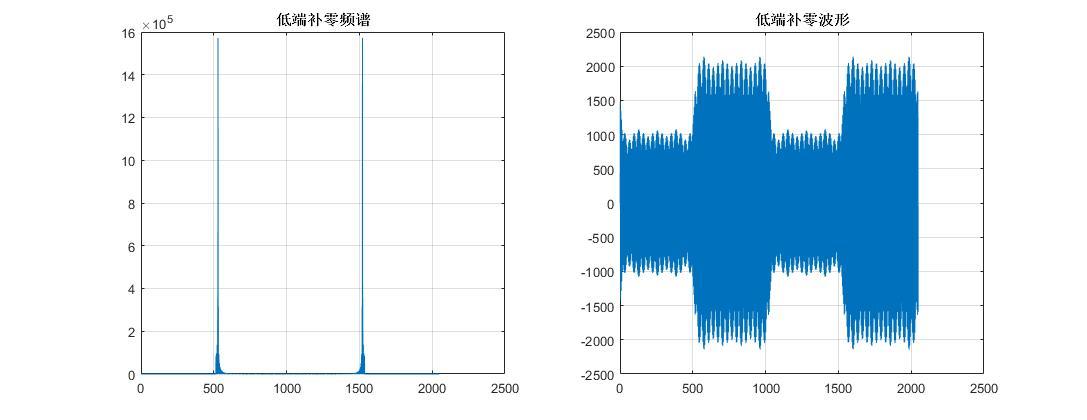 低端补零频谱 波形.jpg1087x420 32.8 KB
低端补零频谱 波形.jpg1087x420 32.8 KB 女声变男声:一样的道理,先做FFT变换,然后在频谱高频端补零,把频谱挤向低端,FFT反变换以后时域波形的频率即被相应地降低了,然后进行抽样即可,matlab模拟结果如下:
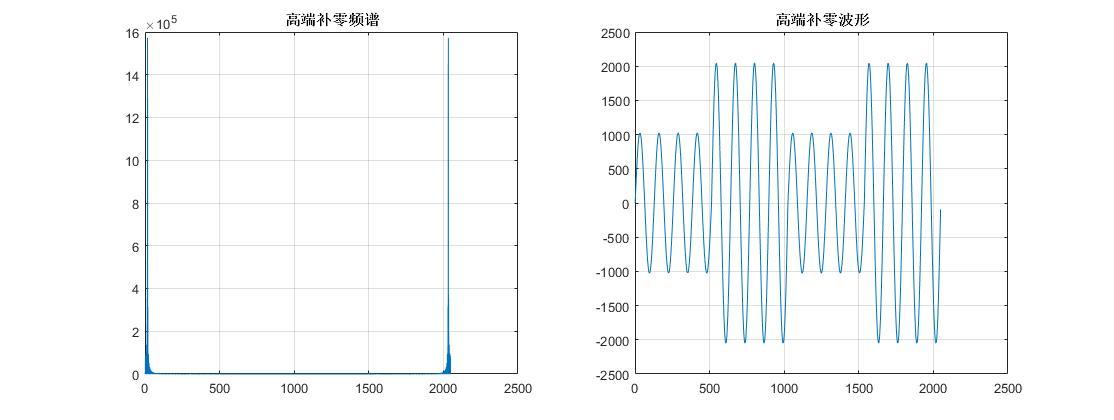 高端补零频谱 波形.jpg1114x420 38.8 KB
高端补零频谱 波形.jpg1114x420 38.8 KB 道理这么简单,可是真要写在单片机里面实现出来就有其他的问题了。关键在于单片机中使用的FFT函数,它只能进行2的整数次幂点数的FFT和IFFT运算。比如说原始序列长度为N点(N为2的整数次幂),FFT以后也是N点,要补零进行频谱抬升或降低的话,为了能使用IFFT函数,必须使补零后序列长度为2的整数次幂,即最小为2N,但是如果把N补零到2N的话,补得太多了,恢复出来音调变化程度超出了想要的范围。为此,尝试过其他几种办法:
1、对N点频域序列抽样得到小于N点的序列,然后在低端补零(升调)或高端补零(降调)到N点,然后IFFT反变换到时域,matlab模拟结果是时域波形丢失了后面一部分;
2、既然会丢失后一部分时域波形,那就在FFT之前对N点时域波形序列抽样,然后在后面补零到N点,进行FFT变换,然后再在频域做1中的处理,即在频域抽样然后在高端或低端补零到N点,最后IFFT得到N点时域序列,这一种看起来貌似是可以的,但是在单片机上始终没调出想要的效果:
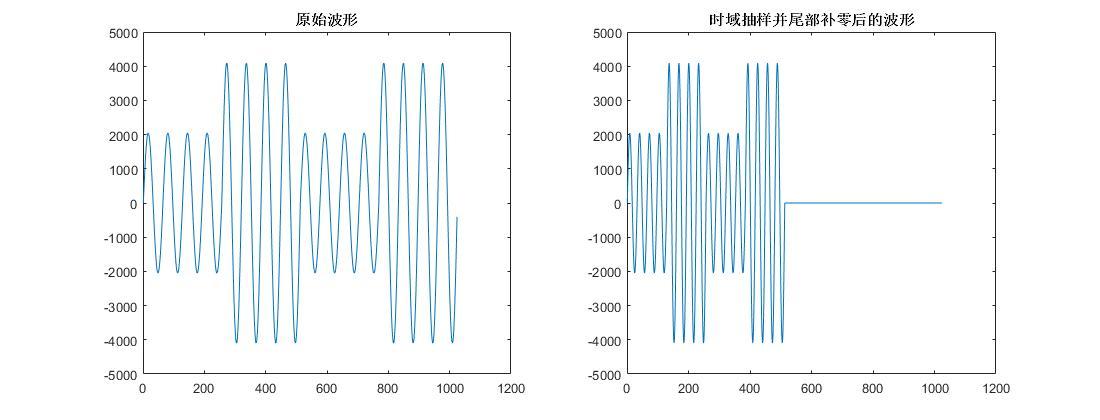 时域抽样补零波形.jpg1100x420 41.8 KB
时域抽样补零波形.jpg1100x420 41.8 KB 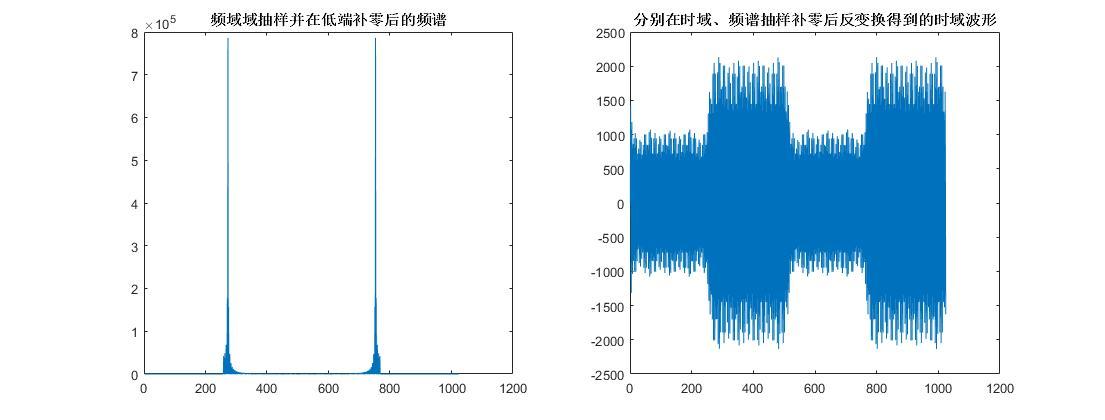 两域抽样补零频谱 波形.jpg1105x420 34.8 KB
两域抽样补零频谱 波形.jpg1105x420 34.8 KB 3、N点时域序列FFT得到N点频域序列,然后进行等间隔插零得到大于N小于2N的序列,然后低端或高端补零到2N点,之后做IFFT变换到时域得到2N点序列,最后时域抽样得到N点时域序列。
这一块是真正考验数字信号处理课程功底的东西,我确实没有弄太明白,很可能是我自己过程中什么地方出了问题,很希望得到高人指点。
最后再上一张全套组装起来的照片,使用充电宝供电、接了喇叭:
 全套.jpg1600x900 795 KB
全套.jpg1600x900 795 KB 终于,貌似比较完整地从头到尾说完了,好像蛮啰嗦的,但这都是自己确实经历了的过程,不喜请轻喷。虽然现在只做到这个程度,但是没办法,现在有更重要的事情,不能在这里花更多精力了,这次的分享也算是一个总结吧,虽然很不完美,但是不得不先暂时做个了断,让自己转移重心,别无他求,图个心安,要是能够得到高人指点的话,那其实这么通宵写到六点半也就更值得了。












 /3
/3 
